


Good Morning,
I envision a world where LLMs are complemented by many types of AI, Quantum computing and a convergence of new kinds of computing architectures. For all the book smarts of LLMs, they currently have little sense for how the real world works and there’s a growing list of “world model” AI startups trying to fill the gap. People won’t trust a one dimensional AI, more on this at the end.
While Generative AI models have their uses, I believe the next decade will fill in some of the physical AI gaps, and allow for things that were previously not possible. Yann LeCun, Fei-Fei Li and others are working towards this end. The likes of Google, Meta, Tencent, Nvidia and others are of course also developing world models.
Robotic brain startups like Physical Intelligence (π) are building general purpose models for physical AI that are basically foundational models for the physical world to help robots learn among other things. Language isn’t enough and models trained on text have inherent limitations. The token based way of predicting the world is just one perspective. A world-model based AI could have advantages over LLMs that understand casualty, and maintain mental models that are more human-like and grounded. This could enable more efficient decision making AIs, to actually make the world a better place inspired by cognitive neuroscience and grounded in empirical experience.
Yann LeCun, , Packy McCormick and many others make a lot of good points about the inherent limitations of LLMs and the merits of World Models, and I think this is important to point out even as Silicon Valley fuels capex that isn’t rational compared to what the future AI will actually be like. Of course that is just my opinion.
My guest contributor today is of Weighty Thoughts Newsletter, a VC on AI and DeepTech. 📚 His book What you Need to know about AI, recently won this year’s American Legacy Award Best Nonfiction . It was also a finalist in the business technology category. Congratulations to James.

Weighty Thoughts ∘˙○˚.•
My Weights Thoughts of the day ⚗️
A little Quantum tangent on our World Models exploration today:
-
Nvidia recently announced Nvidia Ising that the company says might be the world’s first open AI models to accelerate the path to useful Quantum computing. It’s exciting because it’s being piloted by the likes of Academia Sinica, Fermi National Accelerator Laboratory, Harvard John A. Paulson School of Engineering and Applied Sciences, Infleqtion (that is now a public company under the ticker ) , IQM Quantum Computers, Lawrence Berkeley National Laboratory’s Advanced Quantum Testbed and the U.K. National Physical Laboratory (NPL).

-
A new paper explores a significant study that provides empirical evidence for exponential quantum advantage in specific machine learning tasks. While theoretical proofs for such advantages have existed for years, this study is notable for bridging the gap between abstract mathematics and practical application.
A new study suggests small quantum computers could process massive datasets more efficiently than exponentially larger classical systems by reducing memory requirements for key data tasks.

-
IonQ what I would call the only successful public Quantum computing company (so far) recently announced that it won a DARPA contract in their Heterogeneous Architectures for Quantum (HARQ) program. This is fairly bleeding edge, this partnership focuses on creating a networked quantum environment that can integrate different types of qubits (such as trapped ions, neutral atoms, and superconducting qubits) into a single, high-performance architecture. Ticker . The project aims to combine the unique strengths of various qubit species in a cross-modality integration and is an important project. IonQ’s role is rather pivotal as is is focusing on the development of core chips for quantum interconnects to provide the “backbone” that allows these diverse systems to communicate reliably.
-
LLMs are accelerating Robotics: Google released Gemini Robotics-ER 1.6. Gemini Robotics-ER 1.6 has significantly better visual and spatial understanding in order to plan and complete more useful tasks. It enables robots to better pinpoint objects in an image and considerably improves robotic saftey. Overall I’d say it combines spatial reasoning, world knowledge, and agentic vision to allow robots to read a variety of instruments. The company says it understands physical constraints like avoiding liquids or items over 20kg when carrying out instructions. 🤖
Weighty Articles ❚█══█❚ Best of James Wang recently:
What I like about Weight Thoughts is the topic choice helps you reframe the narrative into a more realistic lens. I generally find James fairly level-headed which is a trait I really admire.
-
US Jobs Numbers Aren’t as Bad as They Look
-
How I Utilize AI Agents
-
Oil, Iran, and AI’s Energy Problem?
What will the ‘emerging order’ of AI look like? 🌍
If you have ideas on what the emerging order of AI will look like in terms of national defense, quantum computing, world models, neuro -symbolic AI (NSAI), State Space Models (SSMs), Neuromorphic computing, VLA models, Diffusion models, physical AI or some other paradigm, I’d like to hear from you. The truth is we don’t know what the leading alternatives to LLMs in AI are going to look like by the 2030s.

Must Reads
I’m currently going through the recent 2026 AI Index Report by Stanford which has a lot of interesting slides:

The Rise of AI Anxiety
The report highlights a growing trend of anxiety around AI and, in the U.S., concerns about how the technology will impact key societal areas, such as jobs, medical care, and the economy. AI Populaism isn’t a myth you can explain away, there’s a growing mass rebellion of even business people against AI in the workplace. This according to a new survey of executives that show a world where trust in workslop is very low.
The global survey of 3,750 executives and employees across 14 countries at enterprises with 1,000 or more employees found a systemic disconnect: executives and their employees are describing fundamentally different companies. The survey by SAP-owned software company WalkMe of 3,750 executives and employees found a major discontent growing in large companies across the globe where company mandated AI is often at odds with BYOAI of employees.
Is Gen AI even working in the Workplace? 🛠️
You basically have to take everything you read about AI with a grain of salt. Generative AI adoption or diffusion doesn’t mean it’s a great tool for everything. I’m just saying the survey is pretty stark:
-
Only 9% of workers trust AI for complex, business-critical decisions, compared to 61% of executives – a 52-point trust chasm.
-
According to the findings, 54 percent of workers reported avoiding their company’s in-house AI tools in order to complete tasks themselves. A full third of workers reported never using AI at all.
-
Executives appear to be pushing Generative AI products for financial incentives, rather than because they are actually good for the company. While workslop issues pile up: 81% of executives believe they have significantly improved productivity through AI, while workers waste 7.9 hours per week dealing with digital frustrations – the equivalent of losing one full working day, every week.
I myself always temper my AI anxiety with great skepticism. This Newsletter reflects this position the best of my ability. I try to find guest contributors from a wide variety of frames of references but who ideally also questions things and the AI narrative on a fundamental basis. We need to be especially skeptical of narratives around AI either from Silicon Valley or Washington, because they don’t represent necessarily the best interests of normal people and non-Americans. For that reason I consider writers like and important people in the AI blogosphere who question things. So with all this added context – let’s get to the point.
Ok, let’s explore World Models a bit more deeply:
World Models Are Interesting. They’re Also Really, Really Hard.
The Data Friction That Made AI Startups Defensible Is the Same Problem Holding Back Physical AI
By , March to April, 2026.

This publication just covered the AMI Labs launch—LeCun’s $1.03 billion bet against the LLM paradigm after twelve years at Meta. cataloged the players, the investors, and the thesis. He also noted, correctly, that he’s “not bullish on world models necessarily” and that they’ll “take at least a decade to fully mature.”
I agree. But I want to unpack why.
The capital flooding into physical AI is staggering. In 2024, World Labs, Skild AI, and Physical Intelligence each raised hundreds of millions. By early 2026, the rounds had crossed into the billions—World Labs at $1B, AMI Labs at $1.03B, Skild AI at $1.4B. That AMI piece covered them in some detail, so I won’t rehash them here.
What I want to do is explain why this wave of investment is addressing a genuinely deep limitation in current AI—and why the obstacle standing in its way is the same dynamic I’ve written about in the context of AI startup defensibility.
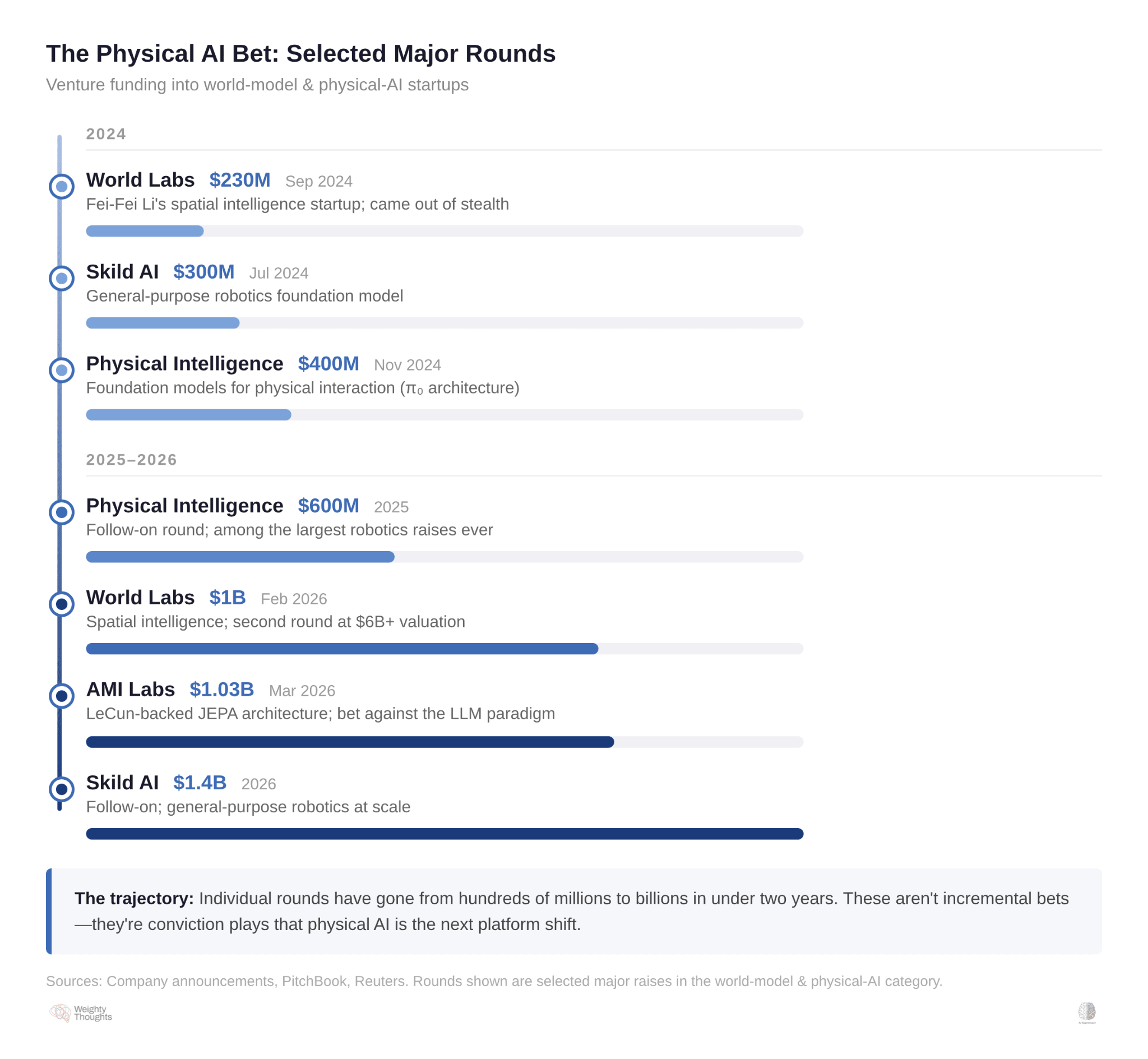
I call it data friction. It’s both the reason world models matter and the reason they might take a lot longer than billions of dollars of venture capital expects.
The Embodiment Problem: Why LLMs Can’t Learn Physics
For my book, What You Need to Know About AI, I spoke with , a professor of computer science at the University of Havana who specializes in language model research. Morffis is a computationalist—he doesn’t believe anything in principle prevents computers from reaching general intelligence. But he’s emphatic that current approaches won’t get us there.
His core critique: LLMs never actually “see” anything. They process statistical shadows of words—vectors that shift based on context. No concept of objects, no experience of the physical world. Just patterns in language. As Morffis told me, “You cannot learn physics by reading about physics. You have to perform experiments in the world to understand how it works.”
My own analogy is that you cannot truly explain color to someone who is blind. Something fundamental is missing when all you have are words. How much worse is this for a machine that has access to nothing but language—and not even all of it, just the specific set of text fed to it? It can describe everything. It has experienced utterly nothing of what it describes.
LeCun has famously called current AI “dumber than a housecat” for this exact reason. Obviously, it’s a statement that’s meant to grab attention and be clickbait. But the point is still right (and, to be fair, he said it long before AMI Labs). Cats remember, reason, and plan. LLMs do none of that. And François Chollet’s ARC-AGI benchmarks keep making this viscerally clear.
OpenAI’s o3 scored 87.5% on the original ARC-AGI. When ARC-AGI–2 launched with harder novel puzzles, o3 initially collapsed to under 3%—while every task remained solvable by untrained humans. But within a year, frontier models clawed back: Gemini 3 Deep Think now scores 84.6% on ARC-AGI–2.
Then ARC-AGI–3 dropped… which then reset the board entirely.
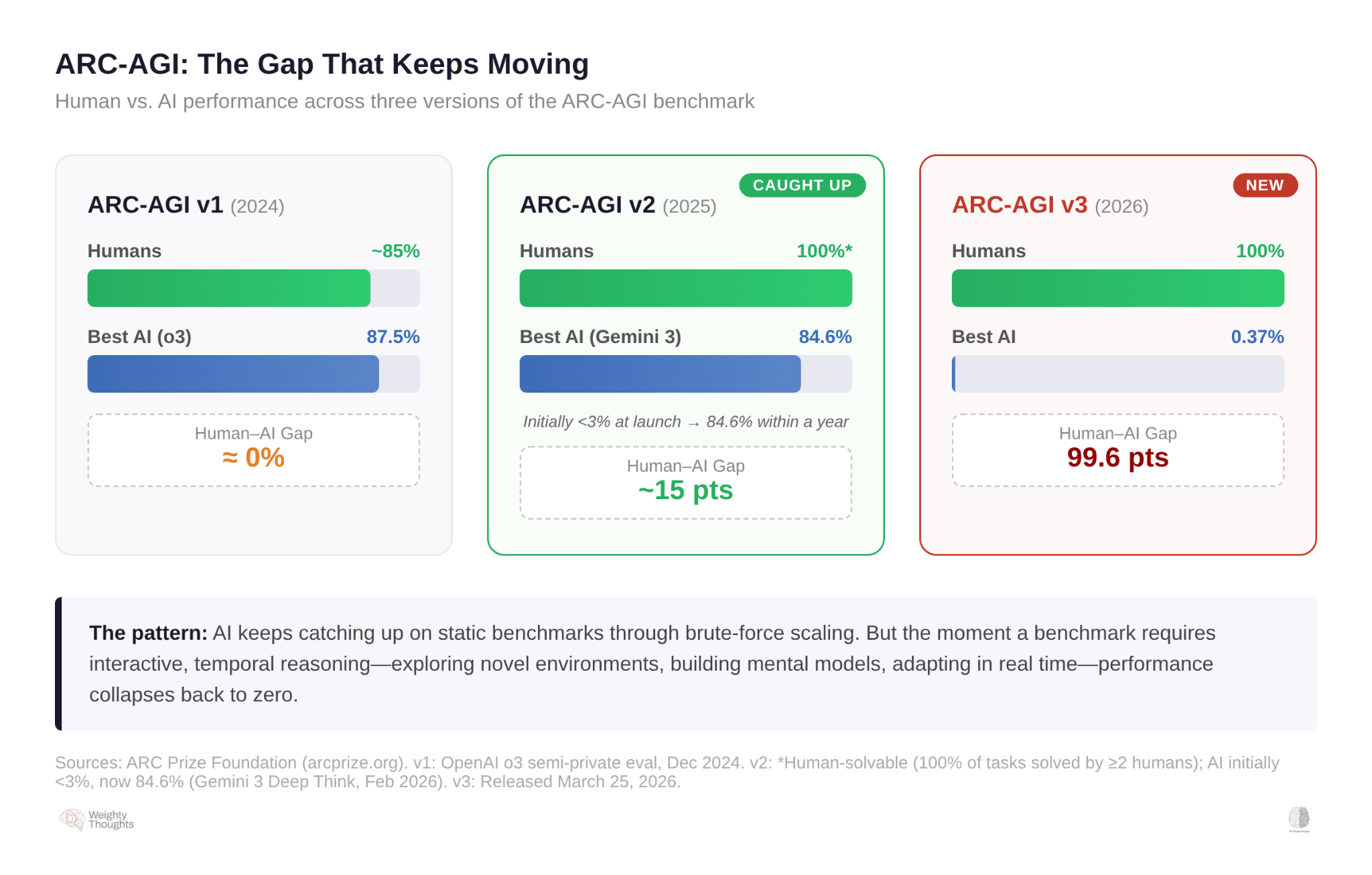
ARC-AGI–3 shifts the format entirely. Instead of static grid puzzles, it presents interactive, turn-based environments—game-like levels with no instructions, no rules, no stated goals. You have to explore, figure out what’s going on, build a mental model of how the environment works, and then act on it. Every level is handcrafted and fully solvable by untrained humans on the first attempt.
has a great interview with the President of ARC Prize Foundation on this topic. ARC-AGI–3 is really just a series of simple retro-style games.
A lot of humans scored 100% (there’s variation, of course—some people just suck at games—but the median is quite high). All frontier AI models scored under 1%. ARC Prize highlighted 0.26% as the frontier score at launch; on the public leaderboard, individual model scores ranged from Gemini 3.1 Pro—the same family that hit 84.6% on ARC-AGI–2—at 0.37% down to Grok at zero.
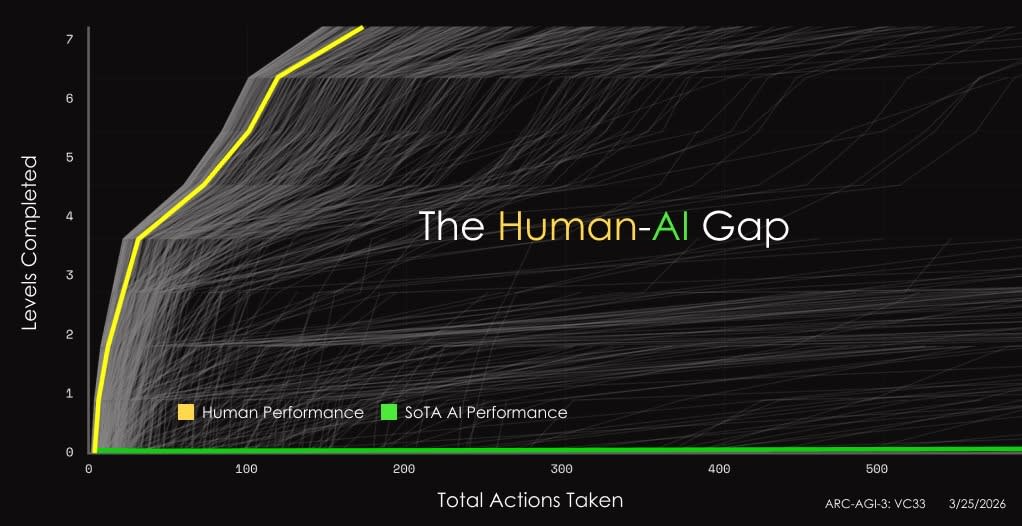
This matters for our discussion because ARC-AGI–3 is explicitly testing what world models are supposed to provide: the ability to explore a novel environment, build an internal model of how it works, adapt on the fly, and plan multi-step actions based on that understanding. ARC Prize describes it as measuring intelligence “across time”—not just pattern-matching on static inputs, but temporal reasoning, exploration, and experience-driven adaptation. In other words, it’s a benchmark for exactly the capabilities that billions of venture capital are chasing.
In my book, Morffis criticizes the AI community for focusing too much on benchmarks (which he’s covered in his own publication as well). Inevitably, we’ll keep seeing benchmarks made… and then get “solved.” It’s less interesting that we see the benchmarks get beaten—it’s more interesting that we consistently are able to create benchmarks that humans can trivially solve, but AI cannot.
AI keeps catching up on static benchmarks through brute-force scaling, but the moment you require the kind of temporal, interactive reasoning that humans do effortlessly… performance collapses right back to zero. Guess what the real, physical world is made up of? Temporal, interactive reasoning that is infinitely more complex than a simplistic 2D game!
This is the intellectual foundation for world models. If LLMs can’t learn physics from text, maybe models trained on video and simulation—models that actually predict what happens in the physical world—can bridge that gap. That’s the idea, anyway. Let’s talk about why it’s so hard… because this isn’t the first time we’ve tried this approach.
Data Friction: The Blessed Curse
I’ve spent a lot of time thinking about what makes AI companies defensible. The short version, which I’ve written about before, is that algorithmic innovation is not a moat. Models are commoditized. Compute is a function of capital. And the only durable competitive advantage in AI is proprietary data that is genuinely expensive and difficult for competitors to replicate.
I call this data friction—the cost, time, and complexity of gathering equivalent information. Digital-native data (web text, user behavior, click streams) is generated with zero friction. Every user action automatically produces a data point. That’s why LLMs could scale the way they did—the entire internet was their training set, and it cost essentially nothing to collect.
Physical-world data is different. Someone has to deliberately record it. A sensor has to measure it. Analog information must be transformed into digital form. Measurement introduces error. Infrastructure costs money. And the data itself is vertical—a dataset of warehouse logistics tells you nothing about kitchen robotics.
More to the point, it’s horrendously expensive.
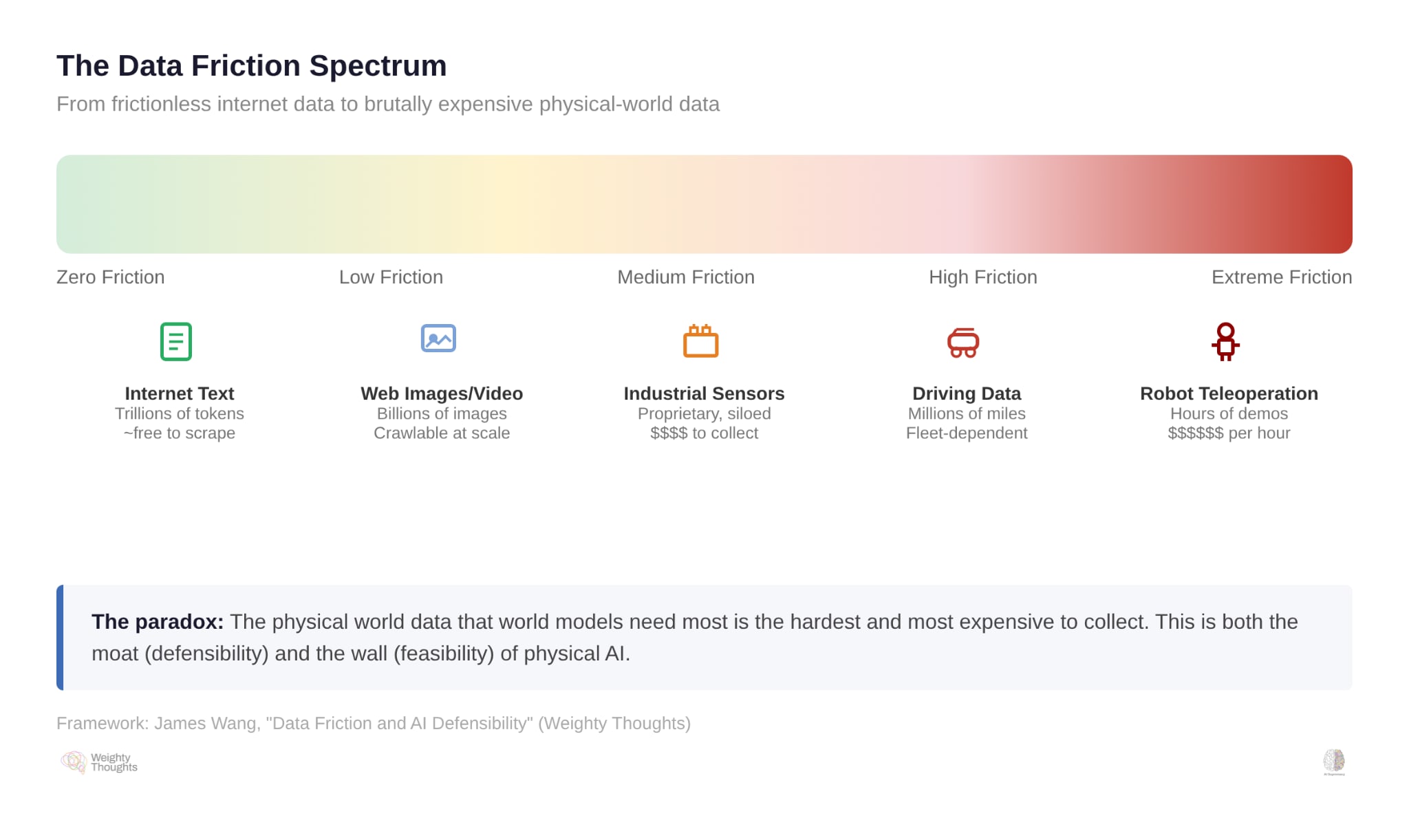
This friction is normally a good thing if you’re building an AI startup. It’s what creates defensibility. A company with years of proprietary clinical data from hospital partnerships has a moat that competitors can’t replicate by writing a check. The pain of collecting the data is precisely what protects you from competition.
But for world models, this same friction is the central obstacle.
LLMs needed vast, diverse text data to learn statistical distributions of language. They got it for free because the internet had already generated it as a byproduct of human communication. World models need an equivalent: vast, diverse data about how the physical world works. How objects behave under force. How materials deform. How liquids flow. How a robot’s actions produce consequences in three-dimensional space.
Where does that data come from? There are really only three options, and they all have problems.
-
Video is the most obvious answer. It’s not only the “closest” to LLMs eating the internet; it is part of the internet. It’s a bunch of “free,” human-generated content there for the (illegal) taking! YouTube sees roughly 500 hours of new content uploaded every minute—over 700,000 hours per day. But video captures observation, not interaction. You can watch someone push a glass off a table. You don’t get the force vector, the material properties, the coefficient of friction on the surface, or the precise trajectory. You see what happened… you don’t get the physics of why.
-
Simulation can generate unlimited interaction data—but sim-to-real transfer is notoriously brittle. A robot that works flawlessly in a physics simulator stumbles on real carpet versus tile, changes in ambient lighting, or objects with slightly different mass distributions. Domain randomization and procedural generation have made this better. But that’s automating the patch-job—it assumes you know in advance what parameters matter. You’re baking assumptions into your “reality” before the robot ever touches it. I have a fun interview with Brandon Basso, Senior Director of Simulation for Cruise, on this topic for self-driving cars. This is an important component of modern self-driving… but it came after we literally had decades of data from these things on the street (mostly with human drivers, both in the case of Tesla and fleets like Waymo/Zoox/Cruise).
-
Robotics teleoperation—a human guiding a robot through tasks while it records forces, positions, and outcomes—is the gold standard. It’s also agonizingly slow, expensive, and narrow. Every warehouse has different shelving, different products, different floor layouts. Every kitchen is different. You can’t record a thousand hours in one environment and expect it to transfer elsewhere. That’s why this data is so valuable… but so grindingly slow and painful to gather.
One of the most common world-model bets is that video pre-training captures enough implicit physics to bootstrap world models, then synthetic data fills the gaps.
Personally, I’d love for that to work. I’m tired of folding clothes and wouldn’t mind welcoming some robot overlords that can take that over from me.
Before that happy scenario can happen, though, the question is whether watching a million videos of glasses falling off tables teaches you enough about gravity to handle a novel object on a novel surface. Maybe it does. I don’t think anyone actually knows yet—and that’s a lot of uncertainty for billions in venture capital.
The Variation Problem
Here’s what makes this especially difficult. Traditional automation works brilliantly in standardized, controlled environments. A car assembly line is designed so every part arrives in the same orientation at the same time. The robot just executes a pre-programmed sequence.
But the industries that most need automation resist it precisely because of variation. In construction, no room is truly square, and no two buildings are identical. In warehouse logistics, orders are random assortments. In food service, dietary preferences are infinite (cheeseburger, but no dairy or gluten, please!). In driving, children (and pets) wander into roads.
World models promise to handle this the way humans do—by understanding the underlying physics rather than pattern-matching from a training set. A human warehouse worker doesn’t need retraining when a new product shows up. They just pick it up because they understand how objects and gravity work. Amazon may need to train their workers on certain things, but no human needs to be trained on that.
The catch is that the long tail of physical variation is worse than the long tail of language. Language has grammar, syntax, and rules. The physical world is continuous, messy, and domain-specific. A warehouse is a different physics problem than a kitchen. A kitchen is a different physics problem than a surgical theater.
Recently, Monarch Tractor, which raised over $240M to address automation in global agriculture, has laid off all its employees, abandoned its headquarters, and appears to be winding down.
If you’ve been following AI, automation, and robots for a while… this should sound familiar.
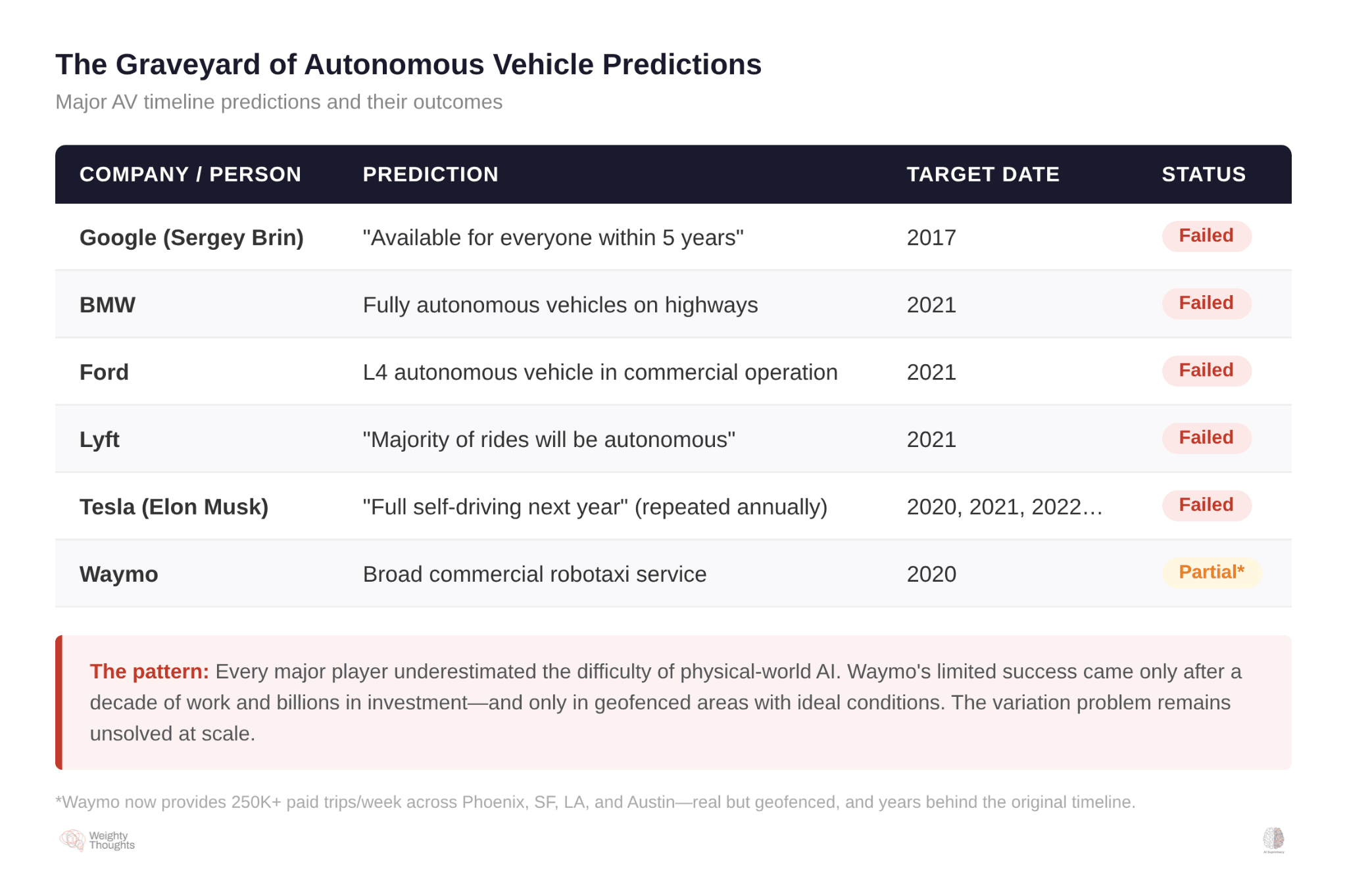
Autonomous vehicles were supposed to be ubiquitous by the early 2020s. BMW predicted full autonomy by 2021. Ford’s CEO promised Level 4 vehicles without steering wheels by 2021. Lyft’s co-founder said most rides would be autonomous by 2021. Everything ended up years behind predicted schedule. The highway was never the real problem. The problem was the long tail—the kid who runs into the street, the construction detour, the emergency vehicle from an unexpected angle.
As I’ve often called them in my own investment thesis on why AI in physical environments is both extraordinarily valuable and torturously hard: exceptions. No matter how “simple” things seem, the real world conspires to break your models.
The variation of ground hardness when combined with natural untidiness of row crops. The impact of slight changes in moisture and humidity on the viscosity of cheese. Humans doing inexplicable things, like deciding percussive persuasion with hammers is the right way to speed up a robot. The world is incredible and majestic in its diversity of massively stupid small variations that ruin everything in physical AI and robotics.
As a smaller VC, I can’t claim to have lost billions of dollars learning these lessons over the years, but I definitely can claim millions.
World models face the same long tail in every physical domain simultaneously.
It’s Really, Really Hard
Let me stress-test the bull case. After all, there is a natural, obvious counterargument to what I just said.
“You don’t need a general world model. You need a surgical one or a warehouse one trained on thousands of hours of domain-specific data.”
Sure, totally fair. That’s actually the strongest argument for world models delivering near-term ROI—narrow, vertical applications in high-value domains. Surgery. Semiconductor manufacturing. Warehouse logistics. You don’t need to solve physics in general. You just need to solve your physics.
I’ll even say, this is exactly what I’ve said myself and done in our own investments. Obviously, I think there’s some merit to this.
But even the narrow case runs into the variation problem. No two surgical teams work the same way. No two hospitals have the same equipment layout. The variation that makes general-purpose world models nearly impossible also makes domain-specific ones harder than they look. The data is more available, but the friction doesn’t disappear. It just gets more manageable.
Maybe that’s enough. I’ve thought so, and some of our bets are panning out here… but the fact that this is so difficult even in narrow cases should inform you how monumental a totally general-purpose world model is.
And if the narrow case feels like new territory, the broader ambition isn’t. The dream of building machines that understand physics from the bottom up has been around for decades—and the obstacle has never been the architecture. It’s been the physical world itself.
In the 1980s and 1990s, robotics researchers attacked this problem from multiple directions. Some tried to represent the world explicitly—encoding Newtonian mechanics, material properties, and environmental constraints into symbolic systems, then using planning algorithms to produce robust behavior. Others, most famously Rodney Brooks at MIT, rejected representation entirely and built robots that operated on layered reactive behaviors—no world model at all, just stimulus-response loops stacked on top of each other. Still others increasingly relied on simulation and learned control policies, training agents inside physics engines and hoping the behavior would transfer to real hardware. These camps disagreed on method. But they ran into a common wall: physical reality was messier, more variable, and more exception-laden than any of their abstractions could handle.

None of it scaled to the general, robust, adaptable physical intelligence that people hoped for. It seems so… intuitive… that this would work. But alas, we see the same, horrifying messiness of the real world.
The symbolic planners choked on edge cases. Brooks’s reactive robots were important—they proved that situated, embodied behavior was possible without heavy computation—but they never generalized into flexible manipulation or long-horizon reasoning. The simulation-trained agents, precursors to today’s sim-to-real pipeline, crumbled when they encountered surfaces, lighting, and object properties that diverged from their training physics. Each paradigm found a different way to discover the same lesson: neat abstractions about the physical world break on contact with the actual physical world.
Bespoke, bottom-up physics models or attempts to “get around” total physics models (but still be one) all didn’t work. This was the same methodology that failed for language models, vision models… basically all of the domain areas that modern AI now excels in… because of data.
Rich Sutton called this The Bitter Lesson. His observation, drawn from seventy years of AI research, is that methods which try to encode human knowledge into systems—hand-crafted evaluation functions, engineered features, domain-specific heuristics—consistently lose to general methods that simply leverage computation at scale.
His takeaway? Stop building overly clever stuff. Just scale the learning. In language, that lesson was vindicated spectacularly: researchers who hand-coded grammar rules lost to people who threw compute and data at statistical models. The internet provided the data; Moore’s Law provided the compute. The Bitter Lesson absolutely won out.
Bitter Lesson in Real World Data
World models are, in a sense, the Bitter Lesson applied to physics. LeCun, after all, as one of the modern godfathers of deep learning, is no skeptic of massively scaled models on data.
LeCun’s JEPA architecture is designed to learn latent physical representations from visual data rather than have researchers hand-code them—exactly the move Sutton would prescribe. Stop engineering the physics. Let the model discover it from data. The deep learning revolution showed that learned features beat engineered ones in vision, language, and game-playing. The hope is that this extends to physical understanding.
But here’s the thing about the Bitter Lesson: you need data! For chess, you can generate unlimited games through self-play. For language, the internet handed you trillions of tokens for free. For Go, AlphaGo could play itself billions of times overnight. The Bitter Lesson works when the learning signal is cheap and abundant.
That’s what we want with world models, after all. That’s the entire point!
Unfortunately, as we’ve said, physical data is tough. And that’s where the analogy breaks. We have the right methodology—learned representations over engineered ones and scale over cleverness. But the Bitter Lesson doesn’t tell you what to do when the data itself is the bottleneck (well, insofar as it does, it says you fail). When you can’t generate unlimited physics experience the way you can generate unlimited chess games. When every hour of real-world robotic interaction costs real money, real equipment, and real time. The bottleneck shifted from “can we represent it?” to “can we gather enough diverse experience to learn it?”—which brings us right back to data friction.
The data problem, meanwhile, isn’t just about scale—it’s about diversity. Internet text contains the full breadth of human knowledge in a single training set. Physical interaction data is narrow and domain-specific. Warehouse manipulation tells you nothing about surgery. The vertical fragmentation that creates AI moats—which I’ve written is the only real defensibility in AI startups—also prevents the cross-domain generalization that would make world models genuinely transformative.
And a deeper critique by folks like (and historically, Marvin Minsky) still applies. Embodied AI as undifferentiated artificial neurons won’t think like humans do. My infant daughter recognized “doggie” after seeing a single dog—with some misclassifications of other four-legged animals, sure, but she grasped the concept immediately. AlexNet, the model for computer vision that helped deep learning burst onto the scene in computer vision, required over a million labeled images to achieve comparable classification in 2012. This difference in sample efficiency suggests something biologically ingrained beyond neurons strung together.
Now, maybe that doesn’t matter. Maybe sample efficiency is irrelevant if you have enough compute and data. LLMs and computer vision models bullied their way through it, after all. However, the honest answer is that nobody knows where the ceiling is for world models trained at sufficient scale. We’re placing billion-dollar bets on both sides of a question that doesn’t have an empirical answer yet.
I can’t say that this will definitely fail… but I wouldn’t be shocked if you told me that we were still “right around the corner” a decade from now.
So Where Does That Leave Us?
The question isn’t whether world models are worth pursuing—they clearly are. The LLM paradigm genuinely can’t get us to physical understanding, and Morffis, LeCun, Chollet, and others have articulated why. Physical AI addresses an architectural limitation, not just a performance gap.
The question is whether the people writing billion-dollar checks for world models understand what they’re actually signing up for. This isn’t a research problem. It’s an operations problem. The companies that win—if any do on a generalizable level—won’t have the cleverest architectures. They’ll have the best data, and the willingness to do the slow, expensive, unglamorous work to get it. Partnering with warehouses, hospitals, and construction firms. Deploying robots that learn from actual physical environments, not simulated ones. Building the data infrastructure that makes physical-world AI trainable.
That’s… expensive… to say the least, since you don’t naturally have people generating this data as digital footprints with their every move. You don’t have, basically, the internet.
ARC-AGI–3 is, in a way, the perfect encapsulation of both the promise and the problem. The tasks it tests—exploring novel environments, building internal models, adapting in real time—are exactly what world models need to do. Humans do it effortlessly. The best AI on the planet scores less than half a percent. The gap between here and there isn’t going to be closed by scaling transformers or throwing more compute at the problem. It’s going to require something genuinely new—and the data to train it on doesn’t exist yet.
The friction is the moat. The friction is also the obstacle. It is the way. That’s always been the real game in AI. World models are a plausible way of trying to solve your way around it. The question, of course, is whether or not these particular bets on world models are the right way.
Who is James Wang
-
James Wang is a General Partner at Creative Ventures, an early-stage, deep-tech venture fund that has invested in AI, synthetic biology, and advanced materials since 2016.
-
He was formerly part of the core investment team at Bridgewater Associates and worked at X, Google’s moonshot innovation lab. He is a board director for companies in AI, healthcare, and robotics.
-
James holds a master’s in computer science from the Georgia Institute of Technology and an MBA from the University of California, Berkeley. He is a regular guest lecturer at UC Berkeley on entrepreneurship and startup financing. He is also the author of the Substack newsletter, Weighty Thoughts, and is the author of the Amazon #1 New Release in Computing Industry History and Generative AI, “What You Need to Know About AI.”
“Understanding AI is a daunting task… This book offers a great starting point for those worried they’ll never catch up.” – Reid Hoffman
Buy the Book and support the author:
Addendum
One of the questions that keeps me up at night is how will Authoritarian faction use and leverage AI?
Witnessing the Russian invasion and unjustified attack on Iran, I have been thinking a lot about this. This article by gives us some geopolitical and macro-economic context of current Middle East impacts:

New Emerging Order could leverage AI for Nefarious Motives
It’s clear how the financial elite leverage LLMs and their products and how real people will benefit or be hurt by it will differ greatly. The push back of normal people against AI is fully justified since the risks it poses to global peace, their livelihood, their relationships and their communities is serious. Like cybersecurity experts and bankers being nervous about the impact of Anthropic’s latest model Mythos, there’s a place in society for AI populism and all attitudes on the spectrum for how we use, don’t use, or believe AI is good or bad.
We need to be cautious, risk-avoidant and consider carefully when the risks of AI outweigh the potential benefits. Governments thus far not protecting us. Our institutions and workplace are not protecting us adequately. AI regulations and our laws are not going to do so anytime soon.

2026 Ushers in Growing Negative sentiment about AI
There’s growing negative sentiment about AI, with Gen Z reportedly leading the way, according to a recent Gallup poll. A new study from Gallup found that young adults have grown less hopeful and more angry about artificial intelligence and we should listen to what people are saying if we are a democratic society.
I’ve read dozens of polls and studies like this and generally speaking, people are starting to realize AI could isolate us further and hurt our ability to nurture relationships and break our ability to create meaning and value in our lives. AI should never be given supremacy over our human qualities and over our humanity. Just saying! Be curious and be cautious about how you use and live in the jagged frontier of AI.
Read More in AI Supremacy

