
[[{“value”:”

Good Morning,
We are on the cusp of Chinese New Year and something is happening that’s a bit dark on the U.S. frontier.
Silicon Valley has adopted a 966 lifestyle for AI research. As models get more fine tuned to agentic capabilities, something remarkable is happening. A few Chinese AI startups are now showing signs of being more innovative at the frontier of open-weight models (than Silicon Valley and the rest of the world), this – with a fraction of the capital and with significantly less access to the best AI chips. How could this be?
After the DeepSeek moment of last year (January, 2025), China has surged ahead in Open-source AI models. A flurry of Chinese IPOs means the following AI startups and open-source incumbents are going to be a big deal:
It’s not just the quality of their models, it’s the pace of iteration. 🚀 The DeepSeek moment of last year snowballed into a very different open-source AI reality.
One year after Chinese startup DeepSeek rattled the global tech industry with the release of a low-cost artificial intelligence model, its domestic rivals are better prepared, vying with it to launch new models, some designed with more consumer appeal. – Reuters
There’s a buzz for what DeepSeek is ready to announce, and high expectations. There’s software, reinforcement learning, LLM training and hardware innovations that DeepSeek is making that has rubbed off on China’s vibrant open-weight LLM ecosystem. (The U.S. has no equivalent).
The bifurcation of closed models and open-models has never been this intense. While American companies get the hype, Chinese models are helping developers build real products.

DeepSeek as a Research Lab is taking a different approach
There is a sense of anticipation because DeepSeek is currently on the verge of its next major release cycle. As of February 2026, the primary focus is on DeepSeek V4, which is expected to launch around the Lunar New Year (Tuesday, February 17th begins).
Rumored to be codenamed “MODEL1,” DeepSeek V4 is expected to be a total architectural overhaul rather than just a minor update. Meanwhile its next flagship model DeepSeek-R2 has been significantly delayed and is still likely perhaps weeks away.
What will be DeepSeek’s next play?
-
Engram: A breakthrough “conditional memory” system that separates factual recall from reasoning. This allows the model to access vast amounts of information (over 1 million tokens) without the usual performance “amnesia.”
-
mHC (Manifold-Constrained Hyper-Connections): A technique designed to stabilize training and improve scalability while reducing energy consumption.
-
DeepSeek Sparse Attention (DSA): This enables an massive 1 million+ token context window. It allows the model to “read” an entire codebase—thousands of files—in one go, enabling true multi-file debugging and refactoring.
-
MODEL1 Architecture: A tiered storage system for the KV cache that reduces GPU memory consumption by 40%, making it much cheaper to run than previous frontier models.
I asked journalist to take a deeper look into DeepSeek’s expected moves in the days and weeks ahead. DeepSeek has been busy behind the scenes the past year and we don’t know its full capabilities as it comes out of stealth so to speak with major releases.
Join Recode China AI for China AI spotlights and deeper resources, trends and stories around the ecosystem.

-
Zhipu AI and MiniMax Just Went Public, But They’re Not China’s OpenAI
-
DeepSeek-R1 and Kimi k1.5: How Chinese AI Labs Are Closing the Gap with OpenAI’s o1
-
The Most Important AI Panel of 2026: Can China Lead the Next Paradigm?
While Western closed-source models double down on AI coding capabilities, Chinese open-source models are showing more agentic, browser and fundamental capabilities. Major IPOs and consolidation is occurring and China’s AI engineering prowess is starting to show ultra competitive results. The convergence of China’s AI ecosystem and AI chip makers hurrying to catch up with the rest of the world in semiconductors and HBM, China’s place in the world of AI is likely on the ascent.
I try my best to give global coverage around AI and also to call upon people with “boosts on the ground” in East Asia. That’s why I respect people like , and so much, they are the ones immersed and connected in the latest AI news in China. You can also get full access to this post soon on Tony’s blog.
But how good will DeepSeek’s latest models be? 🤔
“I believe V4 and R2 will remain among the best open-source LLMs available, potentially even narrowing the gap with leading proprietary models. “ – Tony Peng (former AI reporter for Synced)
That being said let’s try to dig into that anticipation and those key details of what we know before the unveiling event:
👀DeepSeek’s Next Move: What V4 Will Look Like
By Tony Peng
Sparsity is DeepSeek’s sauce to scale intelligence under hard constraints

The widely anticipated DeepSeek V4 large language model (LLM) is expected to meet the public in mid-February, right before the Chinese New Year. V4, DeepSeek’s upcoming generation base model, is supposed to be the largest challenge of open-source models to the proprietary models, and the most anticipated releases in the AI space for early 2026.
According to Reuters and The Information, DeepSeek V4 is optimized primarily for coding and long-context software engineering tasks. Internal tests (per reporting) suggest V4 could outperform Claude and ChatGPT on long-context coding tasks.

2025 was a watershed moment for DeepSeek and the following open-source movement fueled by Chinese AI labs. The release of V3 and R1 upended multiple AI narratives: that only spending hundreds of millions could produce a frontier LLM, that only Silicon Valley companies had talents to train competitive models, that the U.S.-China gap in AI was widening due to chip shortages.
Throughout the rest of 2025, DeepSeek continued churning out notable models, including DeepSeek-V3.2-Thinking and DeepSeek-Math-V2, which won the International Olympiad in Informatics. Yet the widely anticipated DeepSeek-V4 and DeepSeek-R2, which were reportedly slated for release in the first half of 2025, were delayed. According to reports, DeepSeek CEO Liang Wenfeng was dissatisfied with the results and chose to delay the launch.
The Financial Times offered an alternative explanation: DeepSeek initially attempted to train R2 using Huawei’s Ascend AI chips rather than Western silicon like Nvidia’s GPUs, partly due to pressure from the Chinese government to reduce reliance on U.S.-made hardware. The training runs encountered repeated failures and performance issues stemming from stability problems, slow chip-to-chip interconnect speeds, and immature software tooling for Huawei’s chips. Ultimately, DeepSeek had to revert to Nvidia hardware for training while relegating Huawei chips to inference tasks only. This back-and-forth process and subsequent re-engineering significantly delayed the timeline.
Sparsity Through Iteration
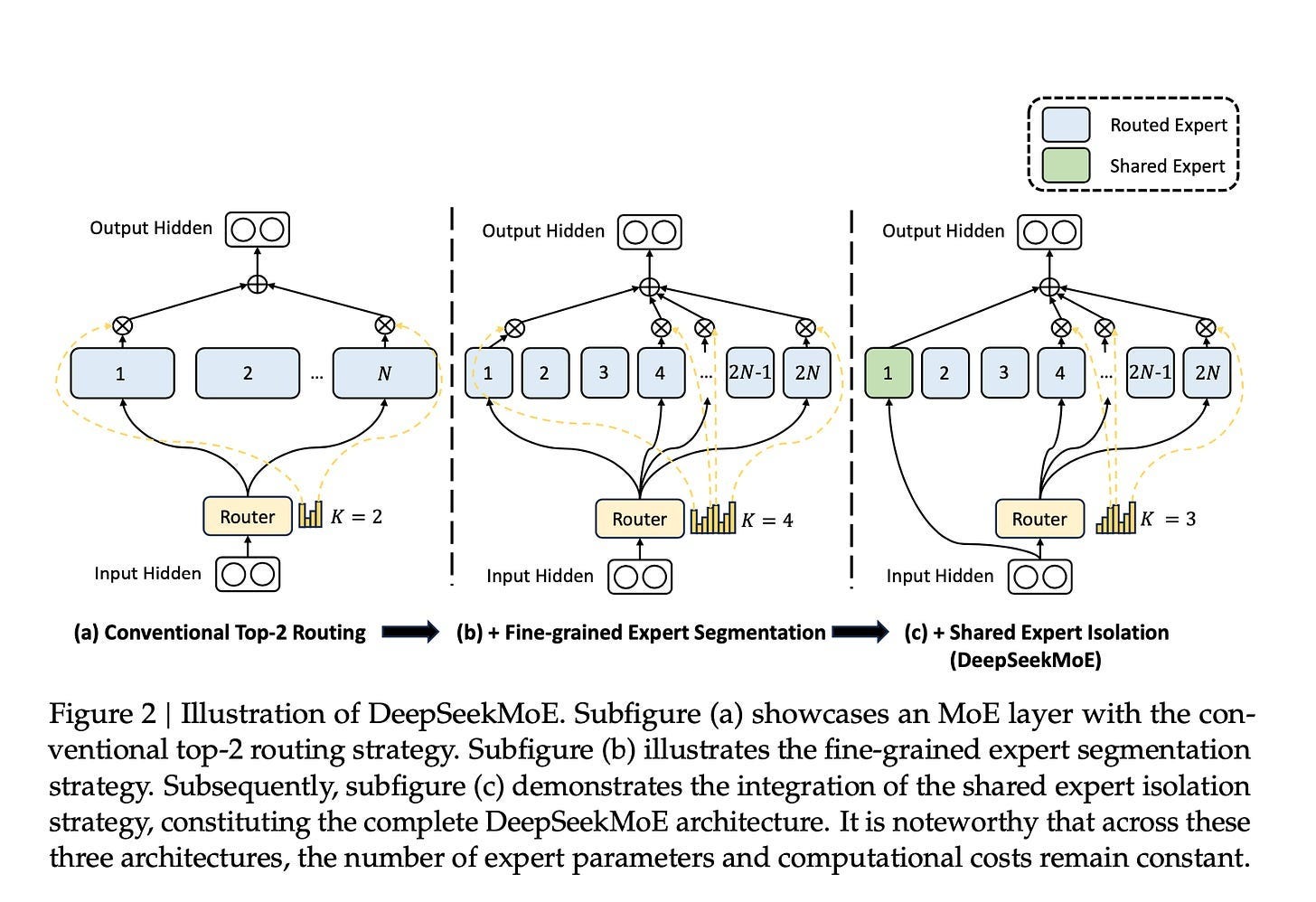
DeepSeek’s architectural evolution has been driven by a consistent principle: Sparsity.
“}]] Read More in AI Supremacy


