

Hello Engineering Leaders and AI Enthusiasts!
This newsletter brings you the latest AI updates in just 4 minutes! Dive in for a quick summary of everything important that happened in AI over the last week.
And a huge shoutout to our amazing readers. We appreciate you😊
In today’s edition:
🧠 OpenAI unveils GPT-5.5 as its most intelligent AI model ever
🖼️ OAI’s ChatGPT Images 2.0 takes lead over Google
💻 Anthropic’s Claude Opus 4.7 leads AI coding race
📊️ Moonshot AI’s Kimi K2.6 narrows ‘open-source gap’
🔍 Google upgrades Deep Research AI with Max mode
💡 Knowledge Nugget: Why Your AI Agents Keep Breaking Your Workflows by Bala Bosch
Let’s go!
OpenAI unveils GPT-5.5 as its most intelligent AI model ever
OpenAI has launched GPT-5.5 (codenamed “Spud”), positioning it as a new class of intelligence that leads across key benchmarks in reasoning, coding, and agentic tasks. The model reportedly matches or even approaches the performance of frontier systems like Anthropic’s Mythos, while overtaking competitors in publicly available benchmarks.
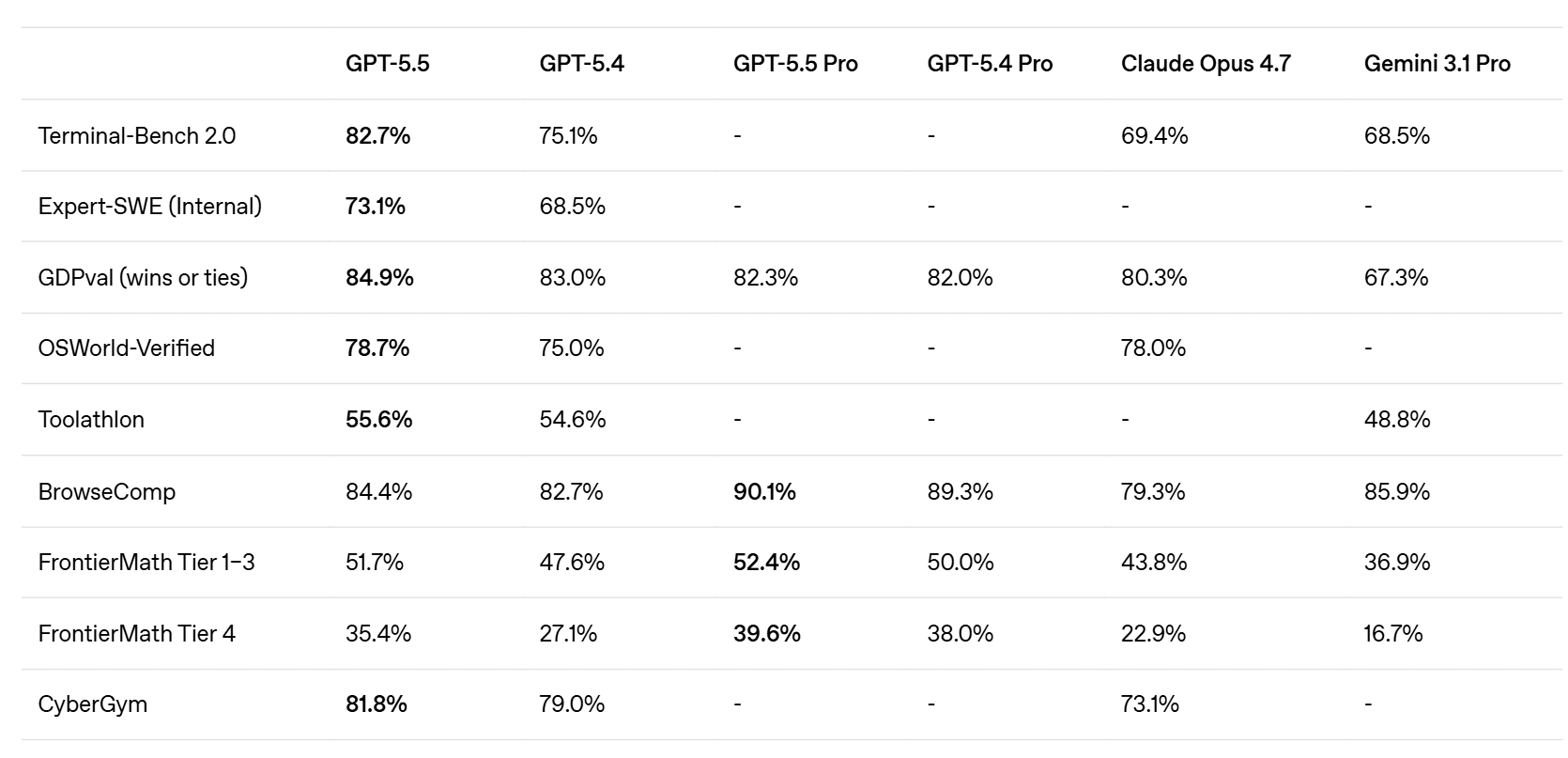
Despite the performance jump, GPT-5.5 maintains similar speed to its predecessor with improved efficiency. OpenAI also revealed it used its own models to optimize GPU infrastructure, hinting at deeper vertical integration. Pricing is set at $5/$30 per million tokens, with the company emphasizing lower costs compared to competing frontier coding models, and broader availability across ChatGPT and Codex.
Why does it matter?
After a stretch where Anthropic led the narrative, the momentum is starting to shift back toward OpenAI. With GPT-5.5 delivering strong performance at competitive pricing, it signals a return to faster iteration and sharper positioning. As competitors face growing scrutiny on reliability and limits, this release gives OpenAI a clear sentiment boost at the frontier.
OpenAI unveils GPT-5.5 as its most intelligent AI model ever
OpenAI has launched GPT-5.5 (codenamed “Spud”), positioning it as a new class of intelligence that leads across key benchmarks in reasoning, coding, and agentic tasks. The model reportedly matches or even approaches the performance of frontier systems like Anthropic’s Mythos, while overtaking competitors in publicly available benchmarks.
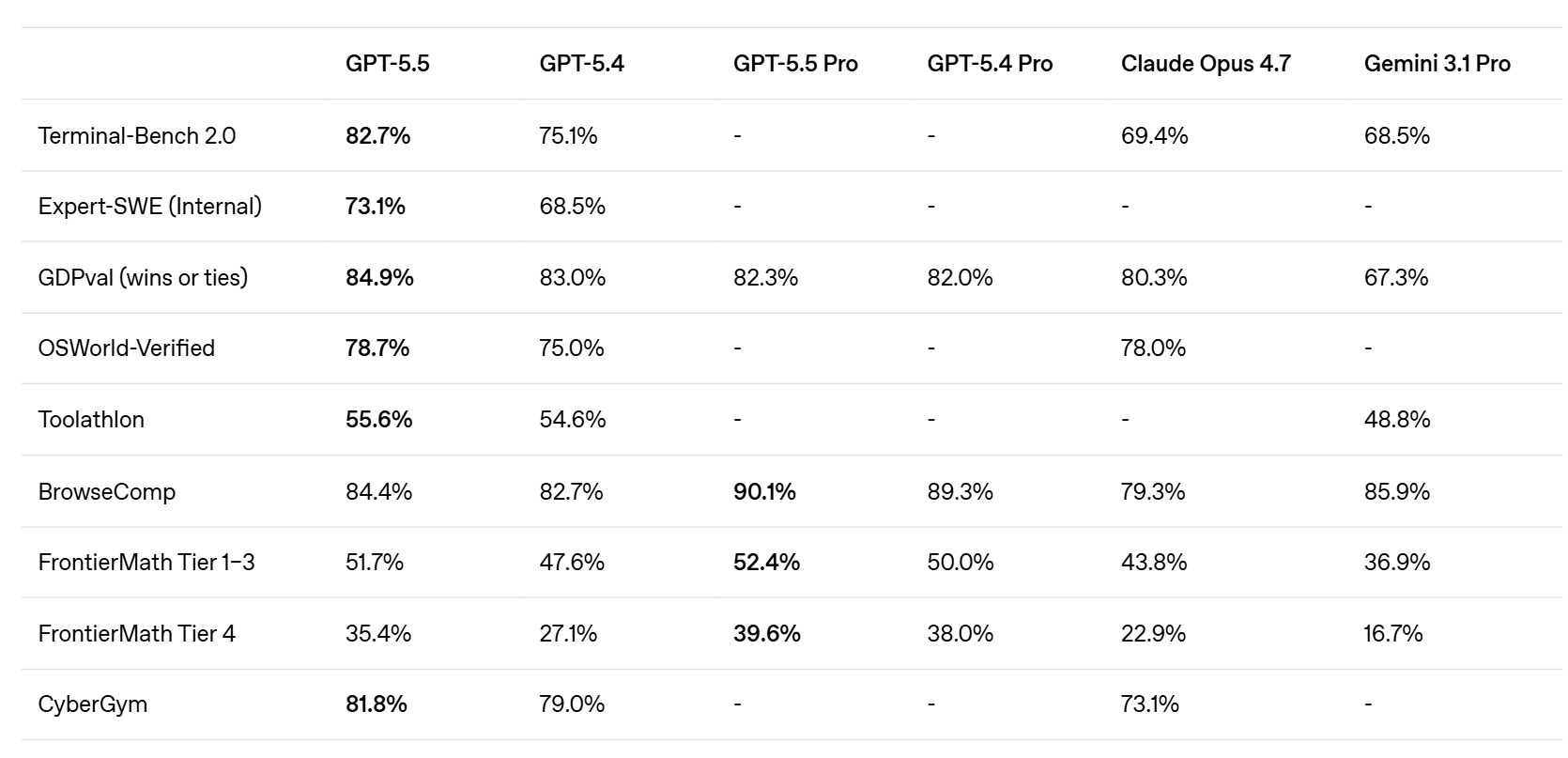
Despite the performance jump, GPT-5.5 maintains similar speed to its predecessor with improved efficiency. OpenAI also revealed it used its own models to optimize GPU infrastructure, hinting at deeper vertical integration. Pricing is set at $5/$30 per million tokens, with the company emphasizing lower costs compared to competing frontier coding models, and broader availability across ChatGPT and Codex.
Why does it matter?
After a stretch where Anthropic led the narrative, the momentum is starting to shift back toward OpenAI. With GPT-5.5 delivering strong performance at competitive pricing, it signals a return to faster iteration and sharper positioning. As competitors face growing scrutiny on reliability and limits, this release gives OpenAI a clear sentiment boost at the frontier.
OAI’s ChatGPT Images 2.0 takes lead over Google
OpenAI has launched ChatGPT Images 2.0, its upgraded image generation model that has already been gaining traction during testing. The new model introduces a major shift; it “thinks” before generating images by planning outputs, searching for references, and checking for errors, making the process more deliberate than previous versions.
The model now ranks No.1 on Arena AI’s text-to-image leaderboard, outperforming competitors across all categories. It also brings practical upgrades like 2K resolution, support for multiple aspect ratios, multilingual text rendering, and the ability to generate up to 8 images at once.
Why does it matter?
OpenAI hasn’t led the image space for a while, and this release puts it back in contention with a noticeable leap. By adding planning and self-checking, the model not only just improves quality; it changes how creative workflows operate, opening up more reliable and controllable ways to generate visuals.
Moonshot AI’s Kimi K2.6 narrows ‘open-source gap’
Moonshot AI has open-sourced Kimi K2.6, a new agentic coding model that matches or outperforms leading models like GPT-5.4, Claude Opus 4.6, and Gemini 3.1 Pro across key benchmarks. It is leading in tests like Humanity’s Last Exam (reasoning) and SWE-Bench Pro (coding), all while operating at a fraction of the cost.
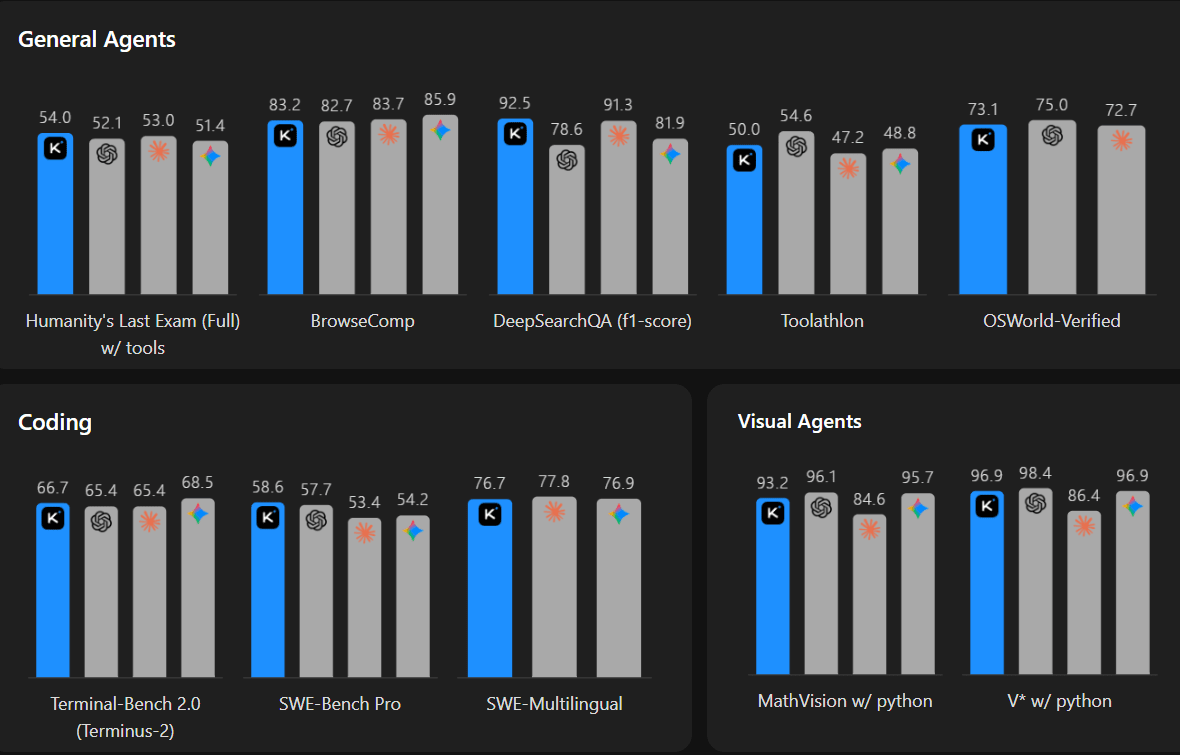
Beyond benchmarks, K2.6 is built for long-running, real-world tasks. The model can work continuously for 12+ hours, handle thousands of tool calls, and even coordinate swarms of up to 300 parallel agents. In demos, it refactored an 8-year-old codebase, while internal agents reportedly ran autonomously for days, signaling a shift toward more persistent, execution-heavy AI systems.
Why does it matter?
Frontier labs often claim open-source models are months behind, but releases like Kimi K2.6 are narrowing that gap faster than expected. With rising demand for long-running agents and growing concerns around cost and limits, K2.6 positions itself as a practical alternative for teams building real-world agentic workflows.
Google upgrades Deep Research AI with Max mode
Google has launched Deep Research and Deep Research Max, two agentic systems powered by Gemini 3.1 Pro that generate full research reports using web data, uploaded files, or connected data sources. Built on the same engine as NotebookLM, these agents can produce structured outputs complete with charts and infographics, moving beyond simple answers to end-to-end research workflows.
Deep Research Max shows strong gains in retrieval and reasoning benchmarks, outperforming previous versions and competing models like Opus 4.6 and GPT-5.4. Users can combine open web search with private data sources via Model Context Protocol (MCP) servers or restrict the system to internal data only. Google is already partnering with firms like PitchBook and S&P to integrate premium financial datasets directly into these workflows.
Why does it matter?
Research-heavy roles like analysts and consultants have long been prime targets for AI, and Google is now turning that into a productized capability. By packaging research workflows into agentic systems connected to premium data, this moves from experimentation to something teams can directly build on.
Enjoying the latest AI updates?
Refer your pals to subscribe to our newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you’ll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
Knowledge Nugget: Why Your AI Agents Keep Breaking Your Workflows
In this article Bala Bosch explains why AI agents keep failing in multi-step workflows, even when prompts are detailed and well-structured. Teams often assume the issue lies in poor instructions, leading them to add more constraints and guardrails. But agents still skip steps, bypass validations, or make decisions that seem logical in isolation while breaking the overall process. The core issue is architectural: agents operate probabilistically and lack awareness of the broader workflow, especially as context gets diluted or lost over time.
This creates a different class of failure. Unlike traditional software errors, these failures don’t throw exceptions; they produce outputs that look correct but violate critical workflow rules. As workflows grow longer and more complex, small per-step inaccuracies compound rapidly. Even high-performing agents can silently corrupt processes when they are responsible for both execution and workflow control, something they are not designed to handle.
Why does it matter?
Most agent failures are being misdiagnosed as model problems, when they are actually system design failures. Teams that keep doubling down on prompts will keep hitting the same reliability ceiling. The real shift is architectural. Until workflows are controlled deterministically, AI will remain a risky layer, not a dependable one.
What Else Is Happening❗
📣 Adobe launched CX Enterprise, an agentic platform that coordinates marketing, content, and customer interactions through networks of AI agents.
🎨 Anthropic launched Claude Design, turning prompts, screenshots, and codebases into interactive prototypes, slides, and marketing assets using its Opus 4.7 vision model.
🧑💻 OpenAI revamped Codex into a unified app with ChatGPT, Atlas, and Codex, adding background computer use, parallel agents, memory, and an in-app browser.
🧬 OpenAI introduced GPT-Rosalind, a life sciences model for drug discovery and research that outperforms most human scientists on certain biological prediction tasks.
⚛️ Nvidia released Ising, an open-source AI model family for quantum computing that automates calibration and error correction, boosting speed and accuracy for next-gen systems.
🛡️ OpenAI launched GPT-5.4-Cyber, a security-focused model for malware analysis and defense, expanding access to thousands of verified users in response to Anthropic’s Mythos.
🧠 DeepSeek previewed V4, open-source models with 1M-token context, competitive reasoning performance, and significantly lower pricing than frontier rivals.
New to the newsletter?
The AI Edge keeps engineering leaders & AI enthusiasts like you on the cutting edge of AI. From machine learning to ChatGPT to generative AI and large language models, we break down the latest AI developments and how you can apply them in your work.
Thanks for reading, and see you next week! 😊
Read More in The AI Edge


{kind=link}