

Hello Engineering Leaders and AI Enthusiasts!
This newsletter brings you the latest AI updates in just 4 minutes! Dive in for a quick summary of everything important that happened in AI over the last week.
And a huge shoutout to our amazing readers. We appreciate you😊
In today’s edition:
🔥 DeepSeek’s new AI rivals GPT-5, Gemini 3
📱 Mistral 3 brings AI to every device
🥇 DeepSeek’s new model hits gold at IMO 2025
🎬 Runway Gen-4.5 tops video leaderboard
🏢 OpenAI reveals enterprise AI habits
💡Knowledge Nugget: The AI Hallucination Debate Is Missing the Point by Max Braglia
Let’s go!
DeepSeek’s new AI rivals GPT-5, Gemini 3
DeepSeek rolled out V3.2 and V3.2-Speciale, two reasoning-focused models that match the performance of top SOTA models like GPT-5, Gemini 3 Pro, and Claude 4.5 Sonnet. The Speciale variant even posted gold-level scores at the 2025 International Math and Informatics Olympiads.
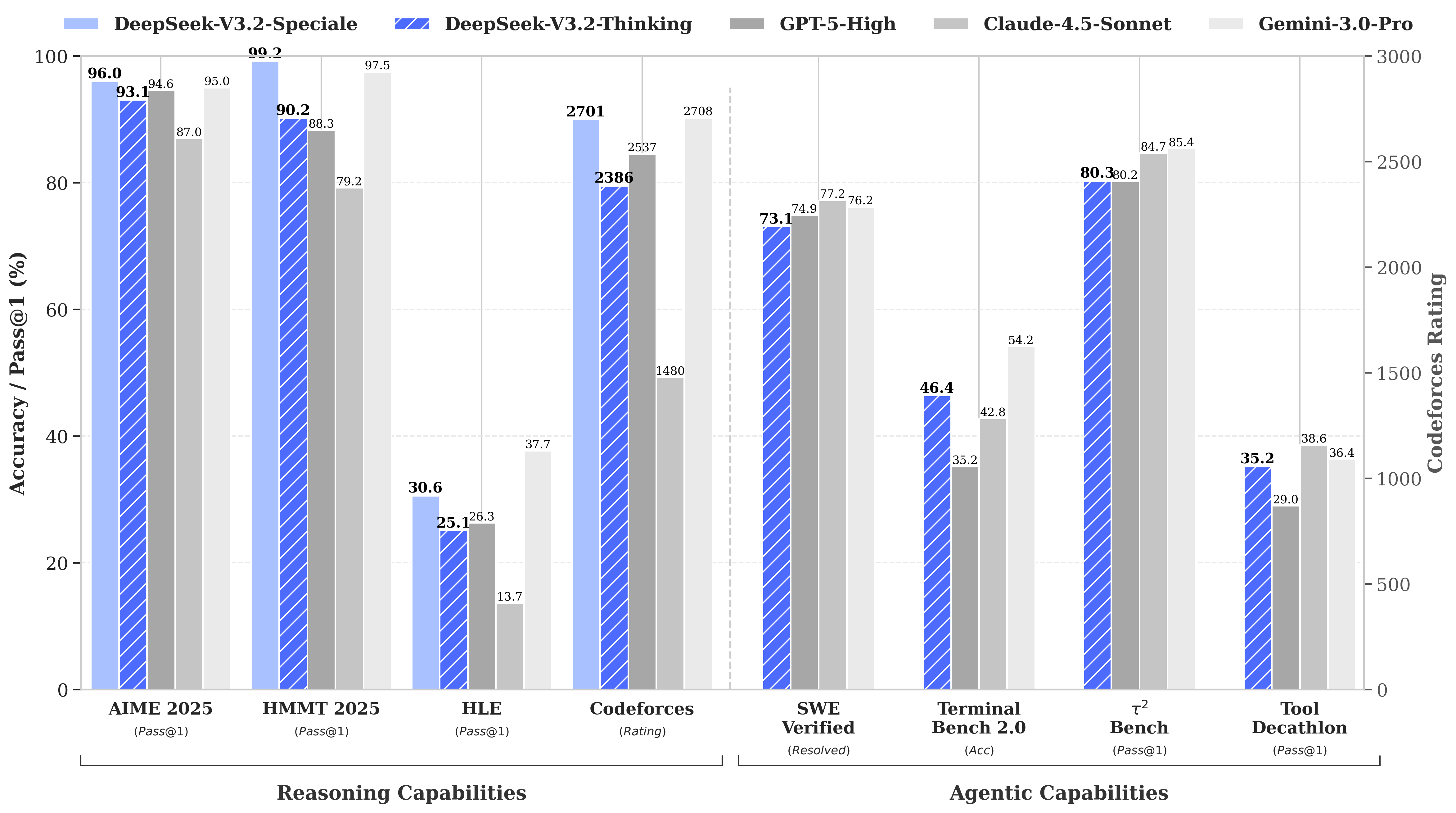
Both models come in at 685B parameters and ship under an MIT license, giving researchers full access to weights that rival frontier AI systems. DeepSeek is also keeping costs low: V3.2’s is priced at $0.28 per 1M input tokens and $0.42 per 1M output tokens, a fraction of what leading commercial models charge.
Why does it matter?
DeepSeek’s V3.2 shows its earlier success wasn’t a fluke and that it can deliver high-level reasoning models at a fraction of U.S. pricing. With performance landing near GPT-5 while staying open and inexpensive, the cost pressure on premium API providers just tightened across the entire market.
Mistral 3 brings AI to every device
Mistral announced Mistral 3, a set of 10 open-weight models ranging from its flagship Large 3 to lightweight variants built for laptops, phones, drones, and robotics. Large 3 targets the same tier as Qwen3 and DeepSeek V3.1, with multimodal and multilingual abilities suited for both enterprise and research workloads.
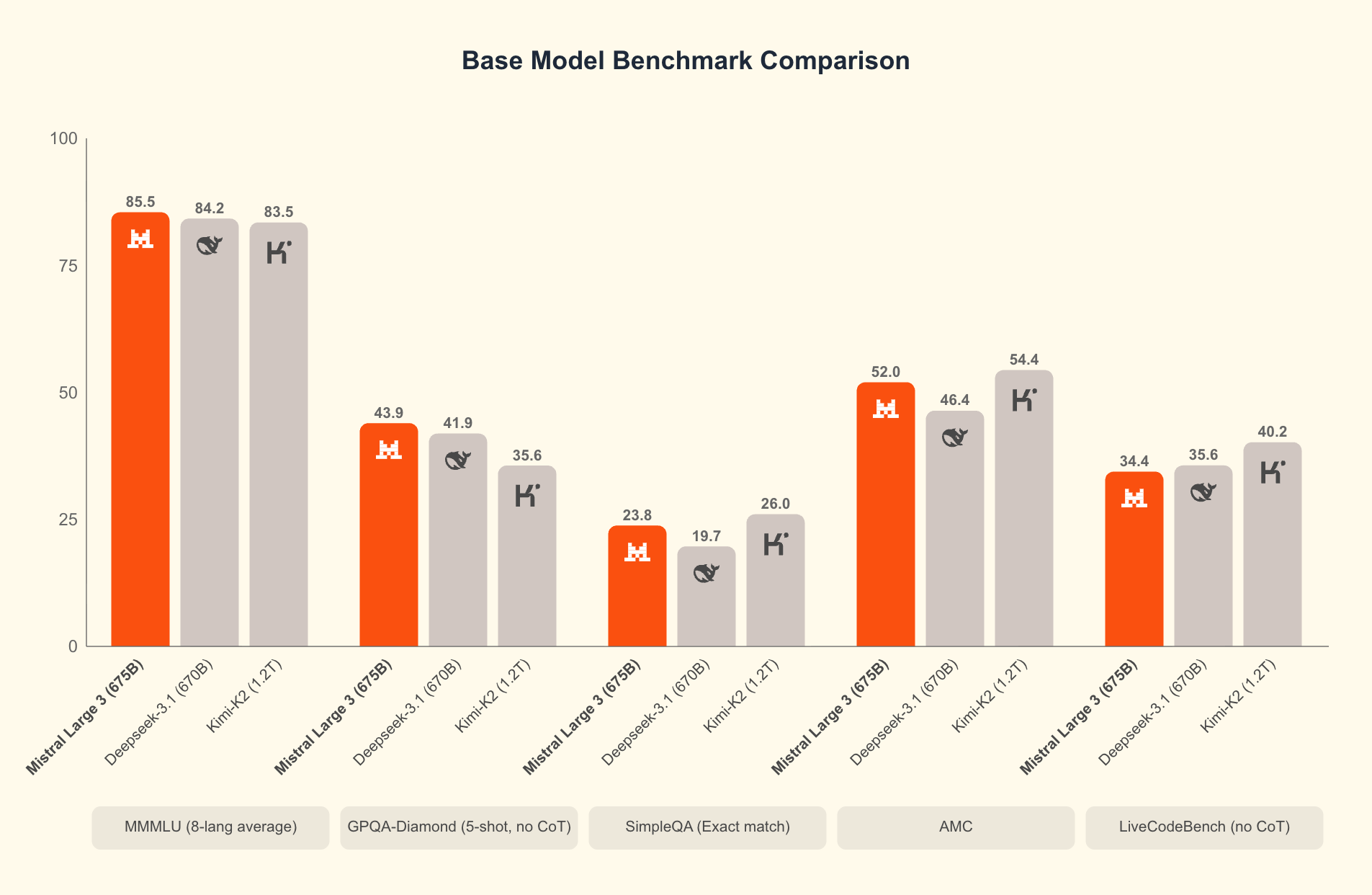
The smaller Ministal 3 models come in 3B, 8B, and 14B sizes across base, instruct, and reasoning variants, all carrying Apache 2.0 licensing and vision support. The smallest models can run locally on consumer hardware without internet access, extending AI into offline and edge environments.
Why does it matter?
Mistral has always had a strong lead in the open-weight ecosystem. These compact variants create a wide surface for developers to ship AI workloads locally, giving Europe a stronger foothold in the on-device AI race.
DeepSeek’s new model hits gold at IMO 2025
DeepSeek released DeepSeek-Math-V2, a research-grade MoE model that matches or beats top human and AI performance on elite math competitions. The model scored 118/120 on the 2024 Putnam and solved 5 of 6 IMO 2025 problems, while posting 61.9% on IMO ProofBench, well ahead of GPT-5 and close to Google’s specialist system.
Math-V2 uses a generator-verifier system where one model proposes a proof and another critiques it, instead of rewarding final answers only. The verifier assigns confidence scores to steps, forcing the generator to refine weak logic and ensuring step-by-step self-debugging of reasoning.
Why does it matter?
DeepSeek is giving the community access to math reasoning once limited to Google’s internal systems. Its generator–verifier design offers a template for agents that can audit their own logic, valuable in fields like engineering, where small errors can be costly.
Runway Gen-4.5 tops video leaderboard
Runway announced Gen-4.5, its latest video generation model that jumps to the top of Artificial Analysis’ Text-to-Video leaderboard. The model, previously tested under the codename “Whisper Thunder,” claims major strides in realism, motion accuracy, and fine-detail consistency, especially in elements like hair, fabric, and fluid dynamics.
While it supports a mix of visual styles, Gen-4.5 delivers its strongest results in cinematic and realism-heavy footage, producing clips that Runway says are indistinguishable from real scenes.
Why does it matter?
Runway has been steadily moving into professional creative pipelines, and Gen-4.5 looks closer to the cinematic quality studios would want for real production work. The next big leaps will be longer clips and tighter audio or dialogue sync, but the year-over-year jump in visual realism shows how fast AI video is advancing.
OpenAI reveals enterprise AI habits
OpenAI dropped its first-ever “State of Enterprise AI” report, pulling insights from more than a million workplace accounts and a survey of 100 enterprises. With 75% of employees reporting better output quality or faster completion times, and another 75% saying AI lets them handle tasks they simply couldn’t touch before.
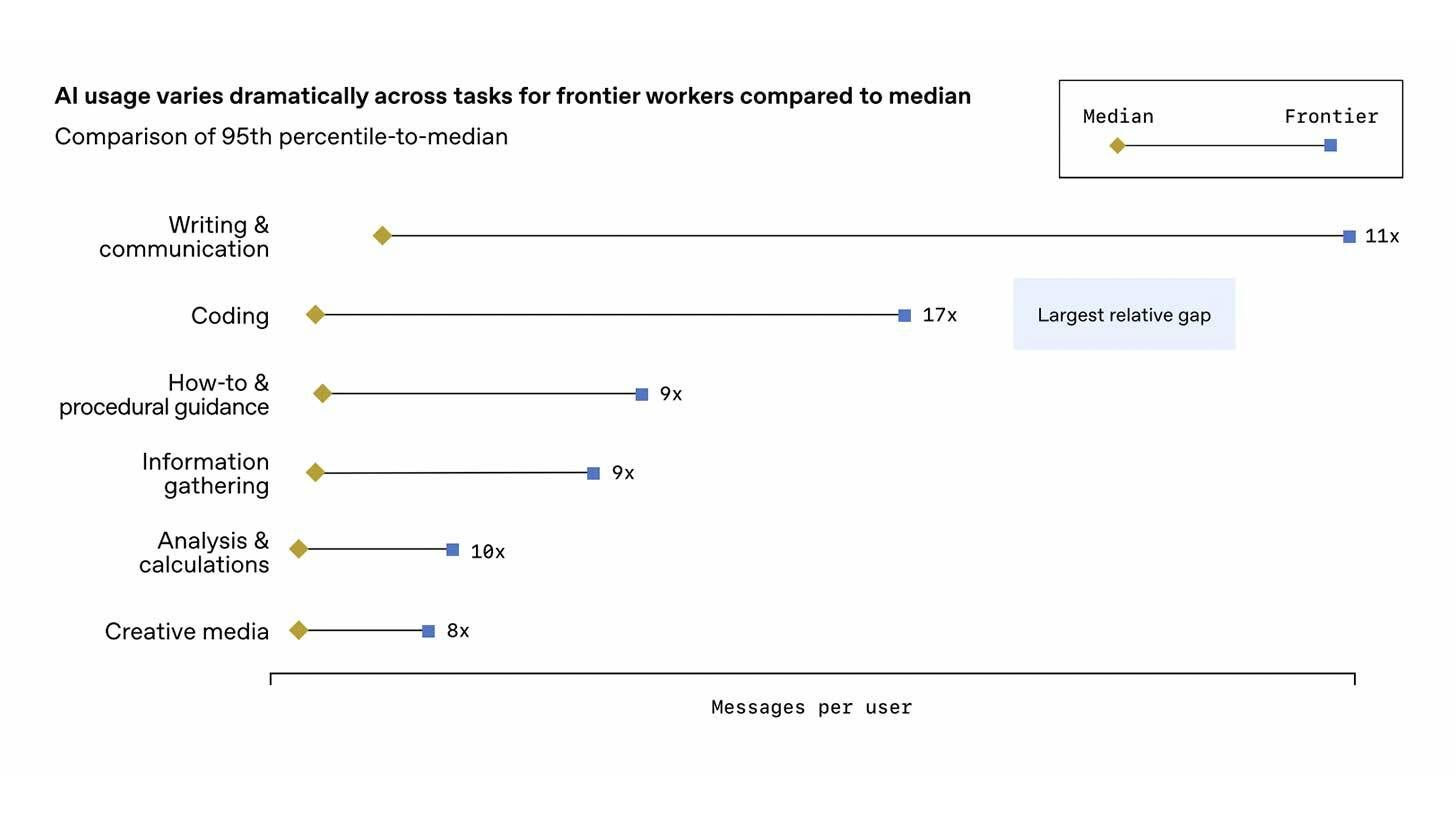
The report also highlights a sharp divide between casual users and power users. The top 5% message ChatGPT 6x more than the median worker, and top coders show a striking 17x gap. On average, business users save 40–60 minutes each day, while heavy adopters shave off 10+ hours per week, hinting that mastery compounds productivity far faster than basic usage.
Why does it matter?
OpenAI’s data highlights how quickly AI is reshaping day-to-day work. The most striking signal is that 75% of employees are now completing tasks they couldn’t tackle before, pointing to a shift where AI expands what teams can produce and opens new cross-functional capabilities across the workplace.
Enjoying the latest AI updates?
Refer your pals to subscribe to our newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you’ll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
Knowledge Nugget: The AI Hallucination Debate Is Missing the Point
In this article, Max Braglia argues that the debate around “AI hallucinations” has become a distraction from the real issue: people are using AI for tasks that demand different levels of expertise, risk tolerance, and verification. Practitioners who work in domains they understand can easily review and correct AI output. But others, from translators to educators to legal professionals, experience something entirely different: AI producing confident, fabricated information they have no way to validate.
This leads to what the author describes as a verification paradox. When you have expertise, AI speeds up drafting and iteration. When you don’t, the tool becomes unreliable or even dangerous because you can’t distinguish a minor mistake from a catastrophic one. The article frames this through three zones of use: a Green Zone where AI reliably augments experts, a Yellow Zone where guardrails are needed, and a Red Zone where AI should not be used at all.
Why does it matter?
It reframes hallucinations as a deployment issue rather than purely a model flaw, pushing the AI community to develop more context-aware safeguards and meaningful evaluation methods. This shift is essential for advancing practical safety and responsible real-world adoption.
What Else Is Happening❗
🚀 OpenAI released GPT-5.2, its most capable model family yet for knowledge work, with Instant, Thinking, and Pro tiers showing gains across reasoning, coding, vision, and tool use.
🤖 NVIDIA and the University of Hong Kong launched ToolOrchestra, training small models that outperform frontier AI on Humanity’s Last Exam while being 2.5× faster and cheaper.
🧠 Harmonic’s Aristotle AI solved a 30-year-old Erdős problem in six hours and verified it in Lean, marking the start of AI-driven “vibe proving” in mathematics.
🎬 Kuaishou’s Kling O1 AI handles video creation and editing in one model, letting users generate clips, restyle footage, and make granular edits, outperforming Google Veo 3.1 and Runway Aleph.
☁️ AWS re:Invent unveils Nova 2 AI models, Nova Forge for custom training, three frontier agents, and the Trainium 3 chip, boosting multimodal, voice, and agentic capabilities.
👨💻 Anthropic’s internal study finds engineers using Claude for 60% of tasks, doubling productivity, but raising concerns over skill decay, career uncertainty, and fading mentorship.
📝 Anthropic launched Interviewer, a Claude-powered tool analyzing 1,250 interviews on AI at work, revealing time savings, social stigma, and concerns over job security.
💻 Mistral launches Devstral 2, a 123B coding model rivaling top open-weight models, and Vibe CLI, its first autonomous coding agent for multi-file edits.
New to the newsletter?
The AI Edge keeps engineering leaders & AI enthusiasts like you on the cutting edge of AI. From machine learning to ChatGPT to generative AI and large language models, we break down the latest AI developments and how you can apply them in your work.
Thanks for reading, and see you next week! 😊
Read More in The AI Edge


{kind=link}