

Hello Engineering Leaders and AI Enthusiasts!
This newsletter brings you the latest AI updates in just 4 minutes! Dive in for a quick summary of everything important that happened in AI over the last week.
And a huge shoutout to our amazing readers. We appreciate you😊
In today’s edition:
🧠 Gemini 3 Deep Think dominates reasoning benchmarks
💰 Anthropic’s Claude Sonnet 4.6 cuts AI costs
⚡ OpenAI launches AI coder on Cerebras
💸 MiniMax AI rivals GPT at 1/20 cost
🖥️ Perplexity debuts 19-model AI agent ‘Computer’
💡Knowledge Nugget: AI Killed the SaaS Model. Then It Sent You the Maintenance Bill by Gobi
Let’s go!
Gemini 3 Deep Think dominates reasoning benchmarks
Google just upgraded Gemini 3’s “Deep Think” reasoning mode and the benchmark numbers are hard to ignore. The model scored 84.6% on ARC-AGI-2, comfortably ahead of Opus 4.6 (68.8%) and GPT-5.2 (52.9%). It also posted a new high of 48.4% on Humanity’s Last Exam and achieved gold-medal-level performance in the 2025 Physics and Chemistry Olympiads.
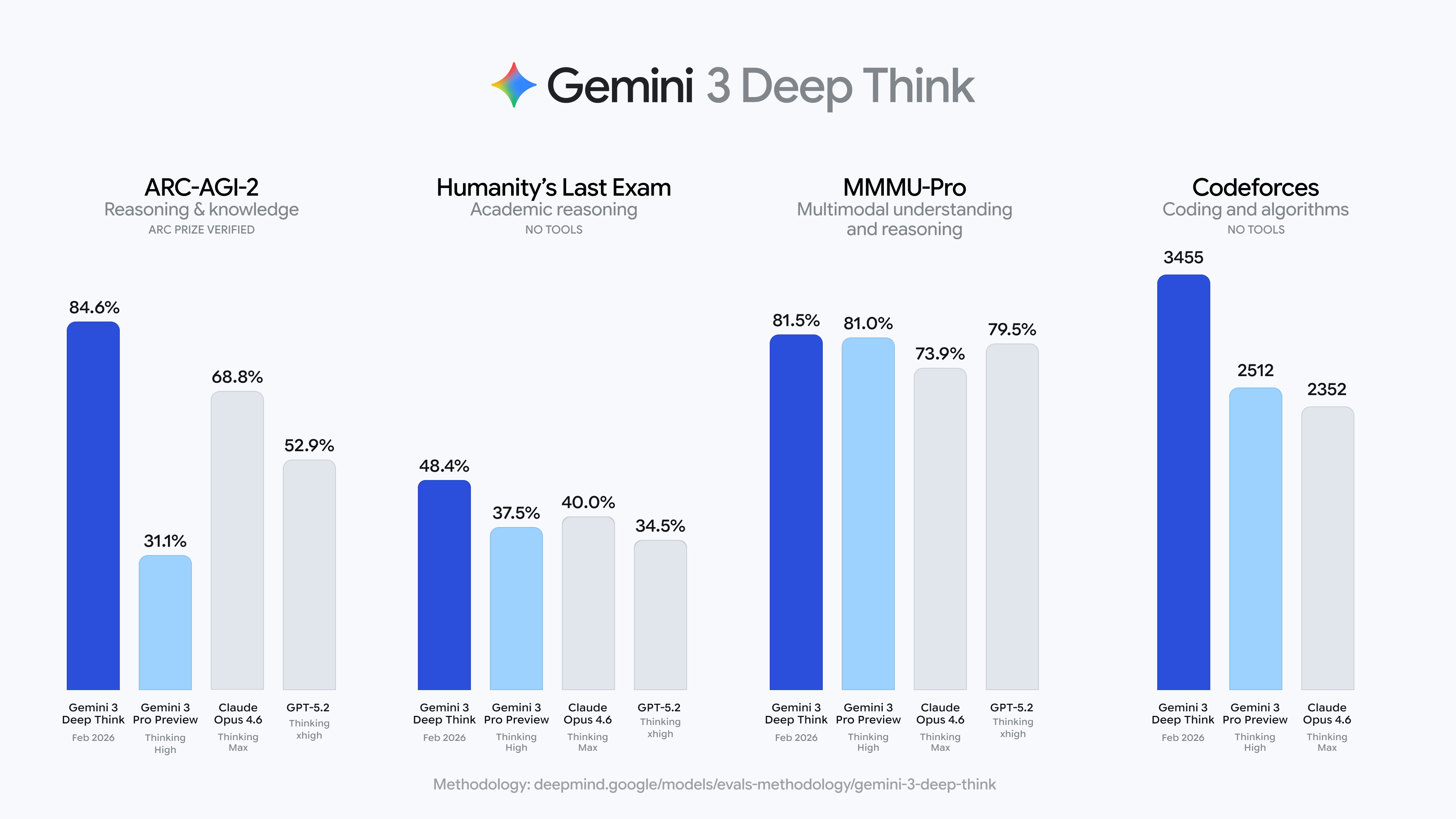
On the coding side, Deep Think reached a 3,455 Elo on Codeforces, nearly 1,000 points above Opus 4.6. Google also introduced Aletheia, a math-focused research agent that can autonomously solve open problems and verify proofs. The upgrade is now live for Google AI Ultra subscribers, with API access rolling out to researchers via early access.
Why does it matter?
After Anthropic and OpenAI traded benchmark wins in early 2026, Google just forced its way back into the spotlight. If the past year was about chatbots getting smarter, this year is about models proving they can compete at research-grade depth, and Google just reminded everyone it’s still very much in the race.
Anthropic’s Claude Sonnet 4.6 cuts AI costs
Anthropic just released Claude Sonnet 4.6, a new mid-tier model matches or nearly matches Opus 4.6 on major coding benchmarks, scoring 79.6% on SWE-Bench Verified, while costing just 1/5 as much to run. It also outperformed Opus on financial analysis and office-task benchmarks, a first for a Sonnet-tier model.
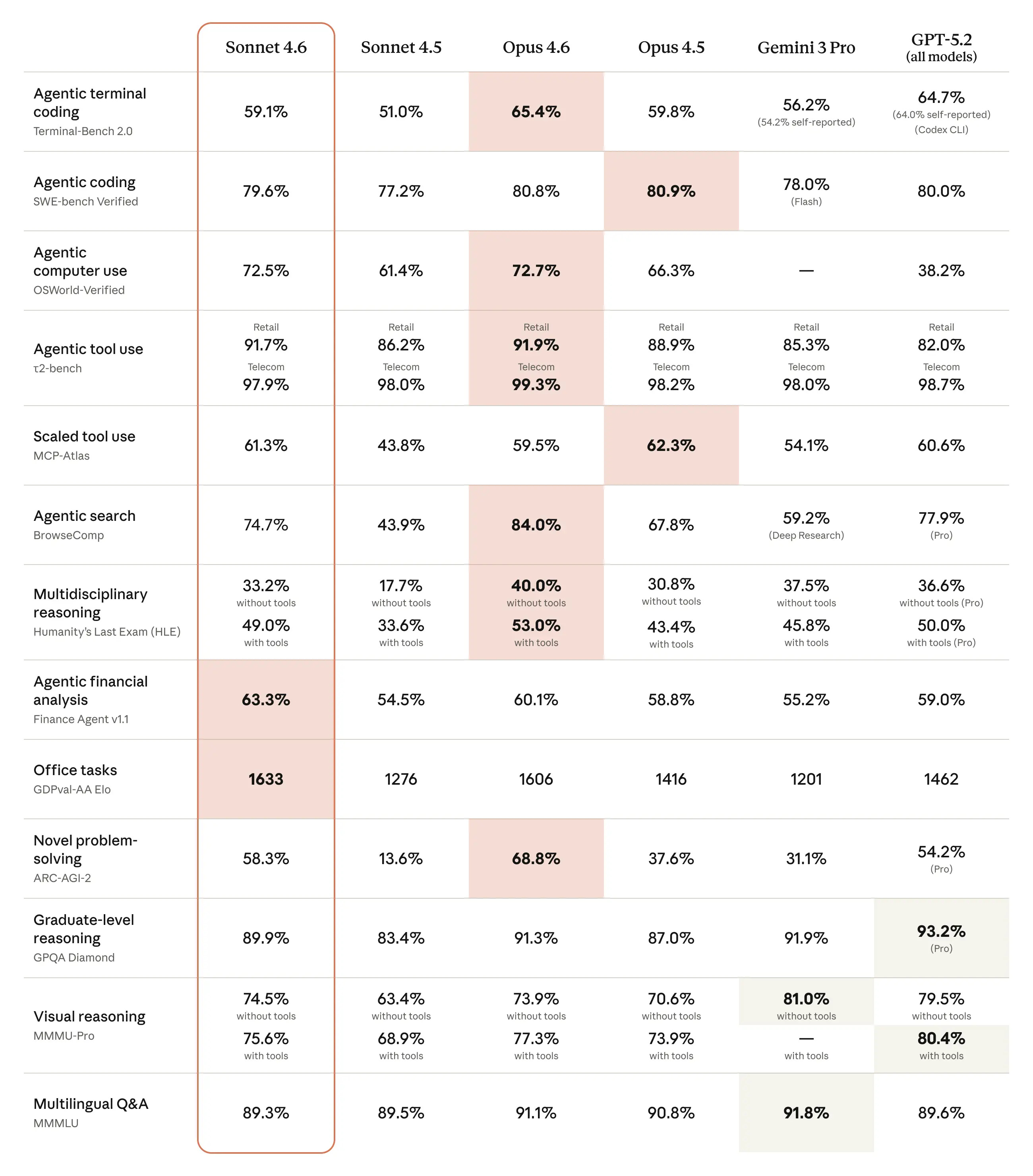
Sonnet 4.6 ships with a 1M token context window and sharply improved computer-use skills, jumping to 72.5% on OSWorld from under 15% in late 2024. Early Claude Code testers preferred it over its predecessor 70% of the time and even favored it over Opus 4.5 in direct comparison.
Why does it matter?
Anthropic is compressing its own pricing ladder fast, pushing near-Opus performance down into its cheaper tier just weeks after the flagship release. As lower-cost global models keep pressuring the market, Sonnet 4.6 feels like a clear move to win the high-volume layer of the agent-driven wave, where cost per task matters as much as raw capability.
OpenAI launches AI coder on Cerebras
OpenAI just launched GPT-5.3-Codex-Spark, a speed-first coding model that can generate over 1,000 tokens per second. Unlike its flagship Codex model, Spark is built for rapid interactive edits rather than deep autonomous problem solving. It sacrifices some benchmark performance but completes tasks in a fraction of the time.
Spark runs on Cerebras hardware, marking OpenAI’s first AI product powered outside its traditional Nvidia stack. The release follows a $10B+ deal with Cerebras and partnerships with AMD and Broadcom, signaling a broader push to diversify compute infrastructure. Spark is rolling out in research preview to ChatGPT Pro users, with limited API access for enterprise partners.
Why does it matter?
By pairing ultra-fast generation with its first production model on Cerebras hardware, OpenAI is turning chip diversification from theory into reality. Real-time coding with near-instant feedback could reshape dev workflows where latency matters more than squeezing out every last benchmark point.
MiniMax AI rivals GPT at 1/20 cost
Chinese AI lab MiniMax just launched MiniMax M2.5, an open-source model that rivals Opus 4.6 and GPT-5.2 on agentic coding benchmarks, but at a fraction of the price. The model shows near-parity performance on key development tests, positioning it as a serious contender in the coding race.
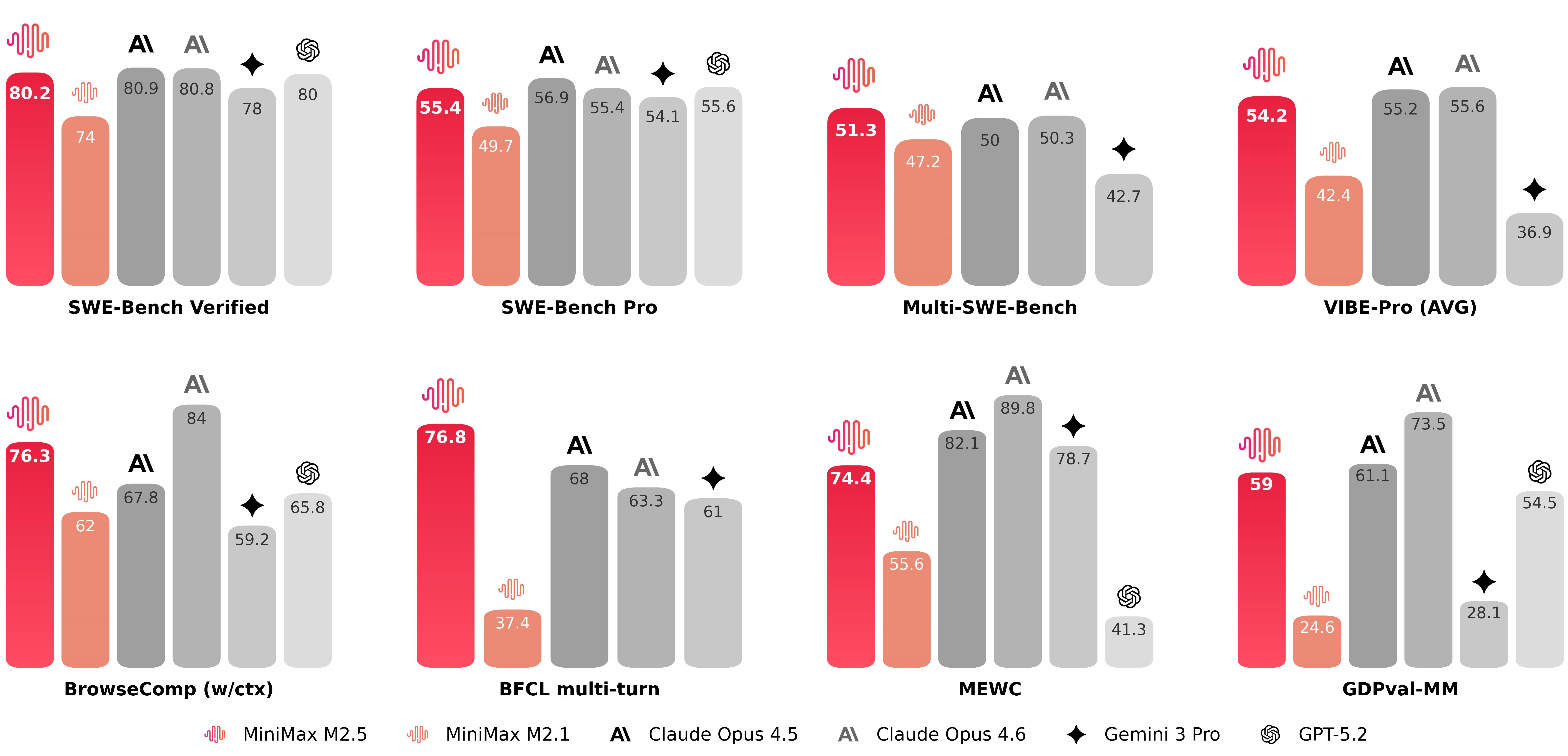
The pricing is where things get interesting. M2.5-Lightning runs at $2.40 per million output tokens, while the standard version costs $1.20, compared to roughly $25 for Opus. MiniMax says the model already handles 30% of its internal company tasks and generates 80% of new code commits. API access is live, with open weights expected soon.
Why does it matter?
Every few months, a new low-cost contender seems to reset the pricing curve — and MiniMax just did it again. Near-flagship coding performance at these rates makes always-on agents economically viable, not just technically possible. As longer autonomous workflows become the norm, cheaper intelligence starts to look less like a feature and more like infrastructure.
Perplexity debuts 19-model AI agent ‘Computer’
Perplexity just unveiled Perplexity Computer, a system that orchestrates 19 different AI models under one roof. Instead of relying on a single model, users describe the outcome they want, and the platform spins up sub-agents that browse, code, connect to apps, and execute tasks autonomously.
Each job runs in its own sandbox and can mix rival models depending on the task. CEO Aravind Srinivas even took a jab at closed ecosystems, arguing that flexibility is the real advantage. Pricing is usage-based, with higher tiers receiving monthly credits and the option to choose which model handles each task.
Why does it matter?
Multi-model flexibility has mostly stayed inside creative tools, but Perplexity is pushing it into a long-running autonomous agent. Mixing 19 models inside sandboxed environments shifts the question from “which model wins?” to “who orchestrates them best?” The edge may now lie in coordination, not just raw intelligence.
Enjoying the latest AI updates?
Refer your pals to subscribe to our newsletter and get exclusive access to 400+ game-changing AI tools.
When you use the referral link above or the “Share” button on any post, you’ll get the credit for any new subscribers. All you need to do is send the link via text or email or share it on social media with friends.
Knowledge Nugget: AI Killed the SaaS Model. Then It Sent You the Maintenance Bill
In this article, the Gobi examine the growing tension between AI-driven software development and traditional SaaS. After sharp swings in software markets in early 2026 and rapid advances in agentic tools, many teams began questioning long-standing SaaS subscriptions. AI can now generate large volumes of working code, shorten delivery cycles dramatically, and automate workflows that once required multiple paid tools.
However, speed has introduced new pressure points. Engineers are spending more time guiding and reviewing agents rather than writing every line themselves, and full trust in AI-generated output remains limited. Code often passes tests but later reveals structural weaknesses, nonexistent package references, or security gaps that only appear under real production traffic. At the same time, many organizations continue paying for unused SaaS licenses due to limited oversight and unclear ownership.
The real challenge centers on operational capability. Teams need strong testing practices, reliable CI/CD pipelines, clear security checks, monitoring systems, and active cost management. Without these foundations, both custom-built systems and SaaS portfolios can quietly accumulate long-term risk and expense.
Why does it matter?
AI has made building software faster than ever, but maintenance now decides the outcome. Teams scaling agentic development without strong engineering foundations risk rising technical debt, while poor SaaS oversight quietly drains budgets. In 2026, the edge belongs to teams that can operate well, not just build fast.
What Else Is Happening❗
🏢 Anthropic upgraded Cowork with department-specific AI agents, private agent stores, and new enterprise connectors, intensifying competition with OpenAI’s Frontier in the agent platform race.
🖥️ Standard Intelligence unveiled FDM-1, a “computer action” model trained on 11M hours of screen video that learns to operate software and even drive a real car by watching and reverse-engineering actions.
⚡ AI chip startup Taalas unveiled HC1, a custom chip hardwiring Llama 3.1 8B to deliver near-instant AI responses up to 100× faster than standard hardware.
🧠 Google released Gemini 3.1 Pro, delivering major reasoning gains and benchmark-topping performance while keeping pricing and its 1M-token context window unchanged.
🧑💻 Tavus unveiled Phoenix-4, a real-time AI avatar model delivering HD, 40 FPS human renderings with dynamic facial expressions and emotion shifts during live conversations..
🎶 Google rolled out Lyria 3 in Gemini, letting users generate 30-second AI songs from text or photos with auto lyrics, cover art, and SynthID watermarking.
🎨 Figma launched Code to Canvas with Anthropic, letting developers convert Claude-built interfaces into fully editable Figma design files and sync changes back to code.
🔐 OpenAI launched Lockdown Mode in ChatGPT, adding stricter tool limits and Elevated Risk labels to protect security-sensitive users from threats like prompt injection.
📐 OpenAI revealed GPT-5.2 independently derived and proved a new particle physics formula, marking what it calls AI’s first original contribution to theoretical physics.
🧠 ByteDance unveiled Seed 2.0, a low-cost model rivaling GPT-5.2 and Gemini 3 Pro across key benchmarks, priced at nearly 1/10 of competitors.
New to the newsletter?
The AI Edge keeps engineering leaders & AI enthusiasts like you on the cutting edge of AI. From machine learning to ChatGPT to generative AI and large language models, we break down the latest AI developments and how you can apply them in your work.
Thanks for reading, and see you next week! 😊
Read More in The AI Edge


{kind=link}