


Good Morning,
As we approach information overload 🐋 on DeepSeek’s marvel, amid clear explanations of what MoE (Mixture of Experts) is, while others questioning if DeepSeek actually caused Nvidia’s stock to plummet, of it this signifies an Open-source revolution, could too much emphasis on scaling laws and size is everything Tech-optimism be misguided after all?
I asked to do a high level overview of what this DeepSeek episode has meant. This even as as Microsoft Azure has rushed to make DeepSeek R1 available.
Jurgen Gravestein works at Conversation Design Institute. He’s a conversation designer and conversational AI consultant, and has been teaching computers how to talk since 2018. He also runs a successful, eponymous newsletter that sits at the intersection of AI, language, and philosophy. It’s fairly useful and entertaining. It’s called:
Teaching Computers how to talk

Selected Articles
-
Agents, Agents, Agents
-
Human Intelligence, Inc.
-
Religion 2.0
-
The Hallucination Problem
-
What AI Engineers Can Learn From Wittgenstein
Some terms around DeepSeek that you might have missed that are important:
What is Mixture of Experts?
“Mixture of Experts (MoE) is a sophisticated machine learning architecture that leverages multiple specialized models, referred to as experts, to tackle complex problems more efficiently. The core idea behind MoE is to divide a problem space into distinct regions, with each expert model focusing on a specific subset of the data. This allows for more tailored and effective predictions compared to a single monolithic model.”
What is Distillation?
“LLM distillation, or Large Language Model distillation, is a machine learning technique aimed at creating smaller, more efficient models that retain much of the performance of larger, more complex models. This process is particularly relevant in the context of large language models (LLMs), which can be resource-intensive in terms of both computational power and memory usage.”
-
What other critical things should we know about DeepSeek events?
-
DeepSeek: Frequently Asked Questions
-
A good tl;dr summary at the top here.
-
Meanwhile Nvidia’s stock has not really recovered and is down around 10% so far this year (as of January 30th, 2025). Trump has pledged tariffs on even Taiwan chips and hitting allies in Asia as well that some believe could impact Nvidia’s margins.
(Alibaba) Qwen & DeepSeek – Is Cheaper better?
“Alibaba has recently launched its Qwen 2.5 (Qwen 2.5-Max) artificial intelligence model, claiming that it surpasses DeepSeek’s latest version, DeepSeek-V3, in various performance benchmarks. The Qwen 2.5 model reportedly excels in problem-solving and reasoning tasks, outperforming not only DeepSeek but also other leading AI models like GPT-4 and Meta’s Llama.”
It’s not clear how far behind or ahead DeepSeek and Qwen models are from Meta’s Llama or how much they lead in open-source LLMs and SLMs at this point. Meta AI’s Llama-4 is supposed to come out in early 2025. So I guess we’ll know more soon. Nor is it clear how China’s cheaper models (including ByteDance) will impact the West and their closed-source business models. The ByteDance model is called ByteDance Doubao-1.5-pro. All of this even as OpenAI gets cozy with the U.S. Government.
Let’s jump into the article.

I find Jurgen’s writing fresh and very original and relevant in today’s quickly changing AI landscape.
By Jurgen Gravestein, January 24th, 2026.
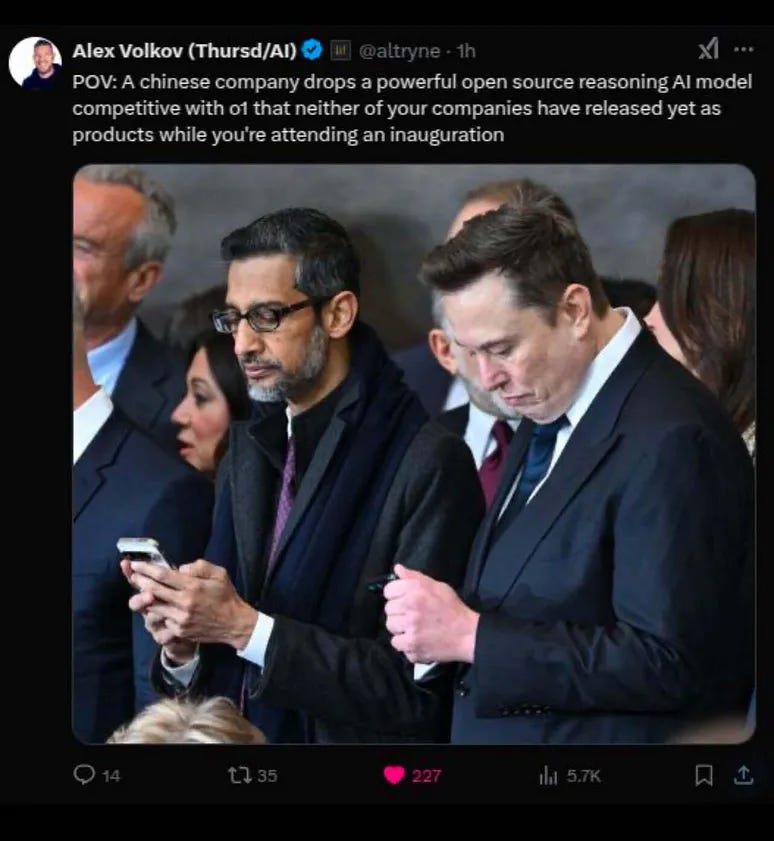
It’s not an exaggeration to say Chinese startup DeepSeek made quite the splash. In a matter of days, DeepSeek has gone from obscurity to becoming the most talked-about company in Silicon Valley.
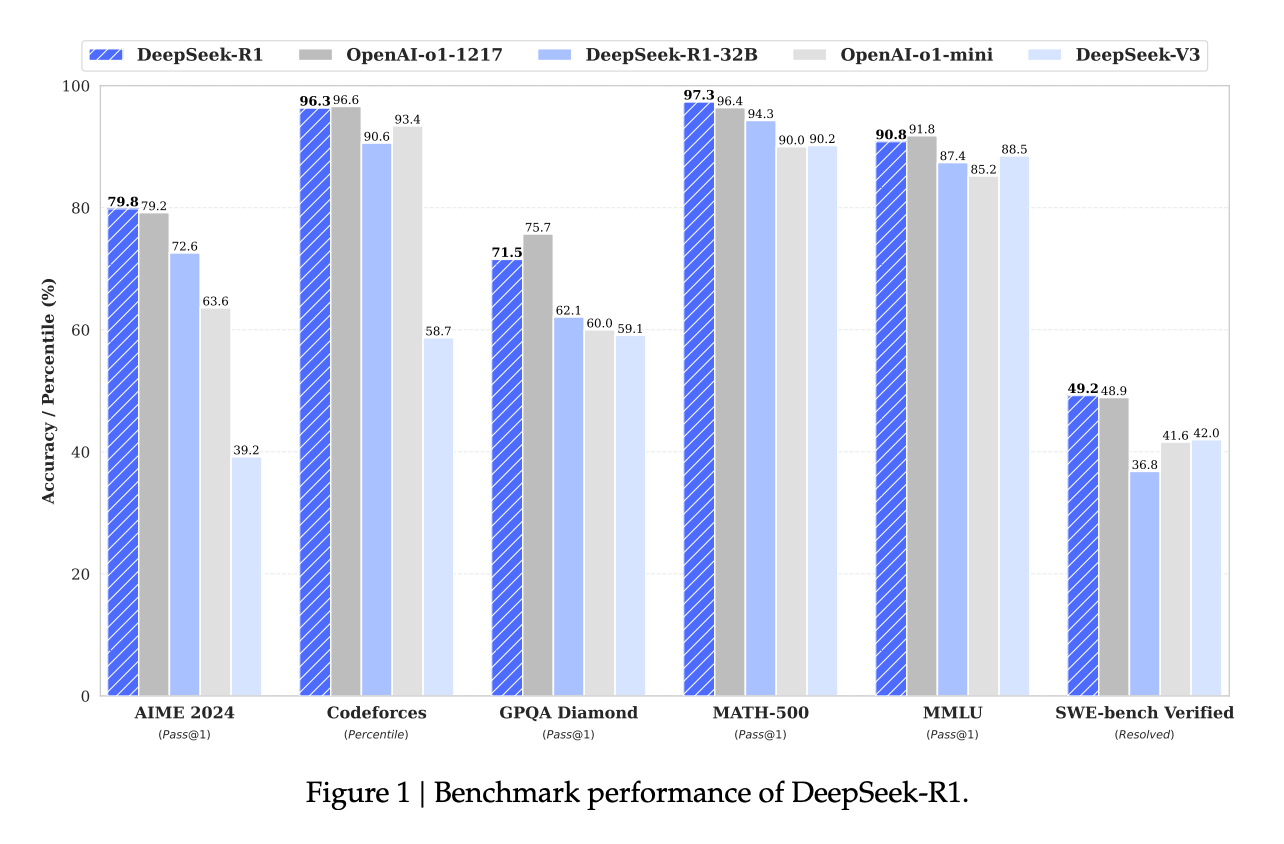
Why? Well, R1, DeepSeek’s first reasoning model of its kind, seems to match performance with OpenAI’s cutting-edge o1 model (and in some cases surpassing it) on a wide variety of benchmarks. And it has done so while adhering to a principle that many believe OpenAI has abandoned: open research.
DeepSeek-R1 is commercially available for free under MIT-license. On top of that, anyone can interact with it through a ChatGPT-like web interface and app – again, at no cost.
The irony isn’t lost on people, with Jim Fan, a senior research manager at Nvidia, tweeting:

A small team with big results
What makes DeepSeek’s story so captivating is that they achieved this with limited resources and a cracked team. Reportedly, the model only took $5.5M dollars to train, although the real costs are probably higher.
A product of necessity, given the US’s embargo on access to high-end chips. Despite this, DeepSeek-R1 not only managed to match OpenAI’s o1 in performance in math, coding, and reasoning tasks, it also surpassed Meta’s Llama models, which were until now considered the gold standard for open source.
What’s even more remarkable is the model’s efficiency – it runs at roughly 1/20th of the cost of o1. In a column for the FT, Zhang, a professor at the Gould School of Law, University of Southern California, explains: “China’s achievements in efficiency are no accident. They are a direct response to the escalating export restrictions imposed by the US and its allies. By limiting China’s access to advanced AI chips, the US has inadvertently spurred its innovation.” Necessity is the mother of invention.
To add insult to injury, DeepSeek published the training recipe in an accompanying paper, laying out in detail how it was made. A surprising move showing they do not intend to guard their secrets.
Some insights on DeepSeek-R1 inner workings:
-
Like AlphaZero, they train purely through reinforcement learning without any supervised fine-tuning;
-
The model demonstrates fascinating emergent behaviors, including naturally increasing ‘thinking time’ during training and developing self-reflection capabilities;
-
Their innovation, GRPO, simplifies traditional PPO by removing the critic network and using averaged reward samples, achieving better memory efficiency*.
(*Short explainer: GRPO stands for Gradient Reward Proximal Optimization, while PPO stands for Proximal Policy Optimization. Both are reinforcement learning algorithms. GRPO is DeepSeek’s modification of PPO that removes the critic network (which estimates how good a state is) and instead uses multiple samples to estimate rewards directly. This makes the algorithm simpler and more memory-efficient, while maintaining good performance.)
In a 2023 interview with DeepSeek CEO Liang Wenfeng was asked about his motivation to pursue open research, he said: “We hope that more people, even small app developers, can access large models at a low cost, rather than the technology being controlled by only a few individuals or companies, leading to monopolization.”
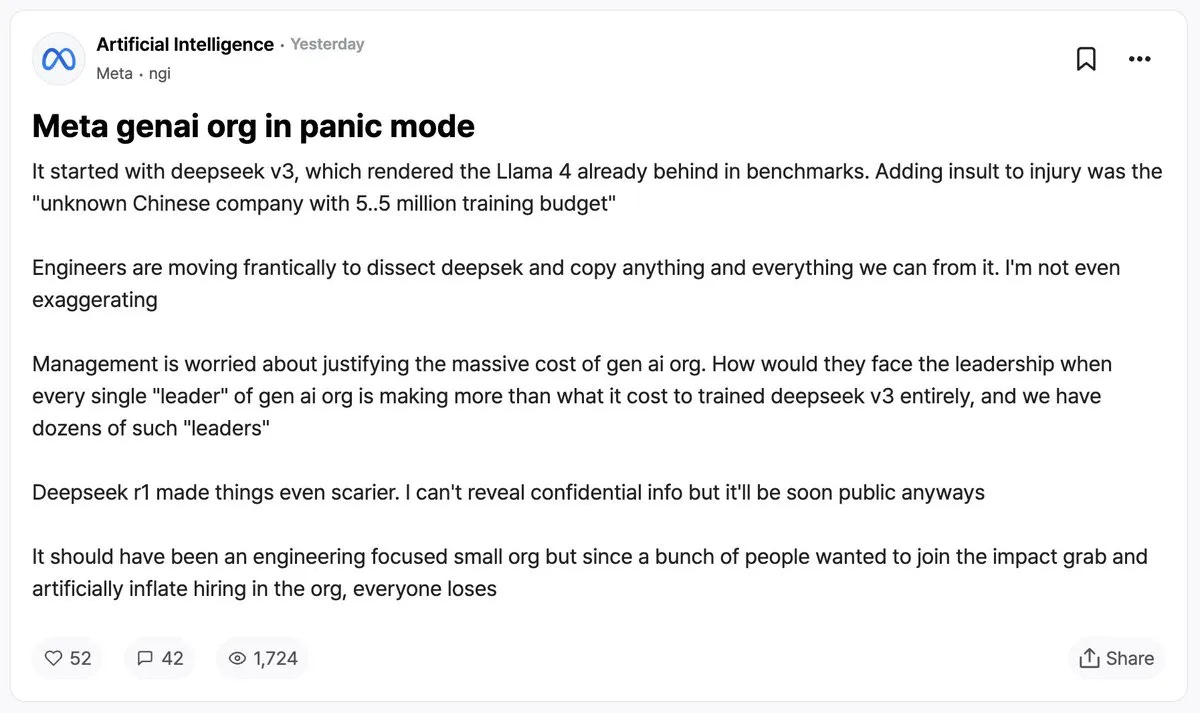
DeepSeek is a serious wake up call
The team and limited resources R1 was trained with have tech CEOs scratching their heads. On Blind, a platform for tech workers to anonymously share stories, a post that gained a lot of traction seemed to suggest that Meta is in crisis mode as it scrambles to understand how DeepSeek outpaced their own efforts in open source AI:
In a public response, Meta’s Chief AI Scientist Yann LeCun attempted to reframe DeepSeek’s success as a triumph for open source in general: “To people who see the performance of DeepSeek and think: ‘China is surpassing the US in AI.’ You are reading this wrong. The correct reading is: ‘Open source models are surpassing proprietary ones.’”
He’s right. For closed source AI, R1 must be a rude awakening. Being free to download, businesses can fine-tune and run the model privately at minimal cost (this is already happening). And companies like Hugging Face have started reverse-engineering it.
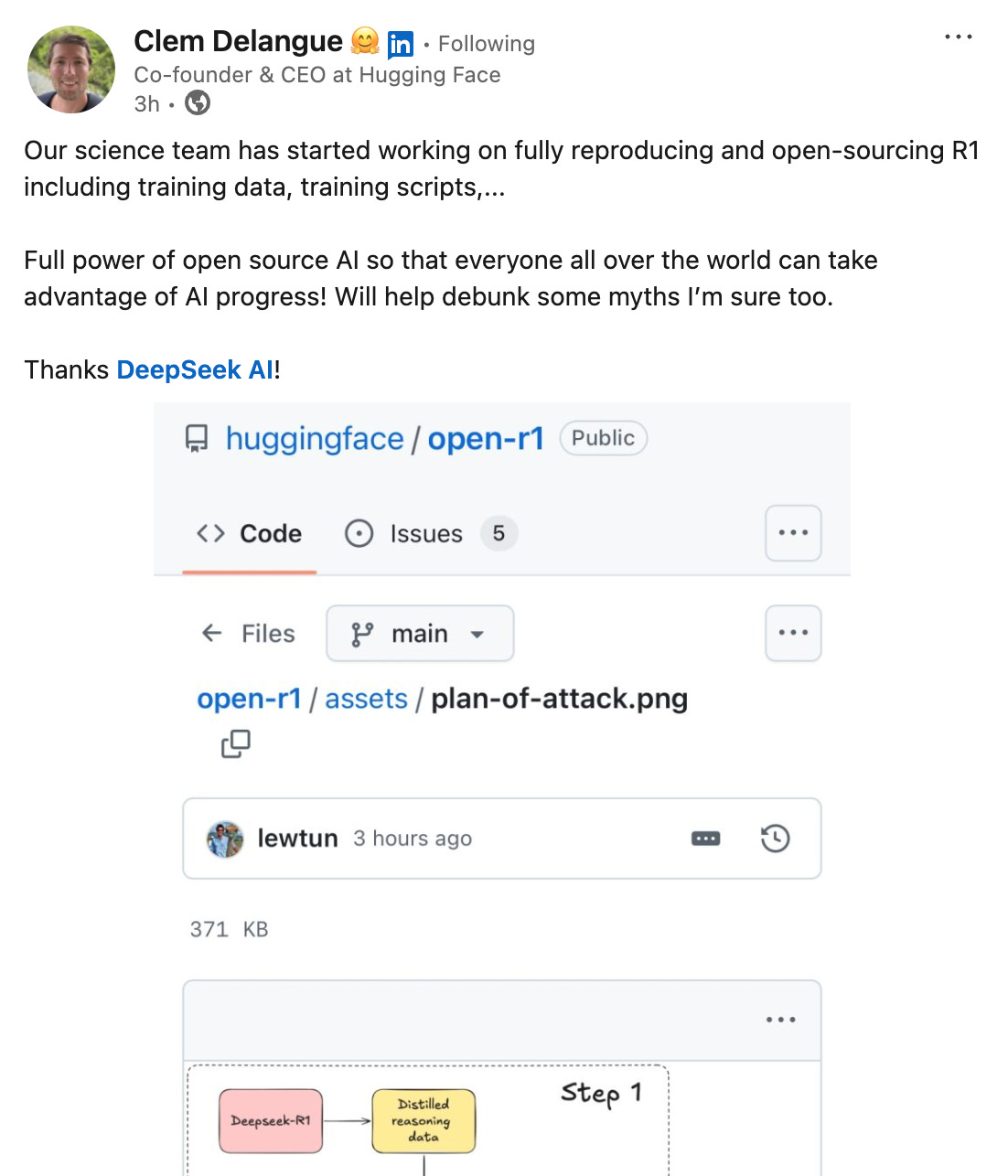
While corporate juggernauts like Microsoft and Meta can afford to waste a few billion in R&D, companies like Cohere, Anthropic, and OpenAI face what must feel like an existential crisis. One is reminded of the leaked internal memo from Google warning, back in May 2023: “We have no moat, and neither does OpenAI”.
What’s becoming increasingly clear is that DeepSeek singlehandedly wiped out almost all of the competitive advantage everyone believed closed AI labs held over open source. On Monday, with a small delay, the markets caught up:
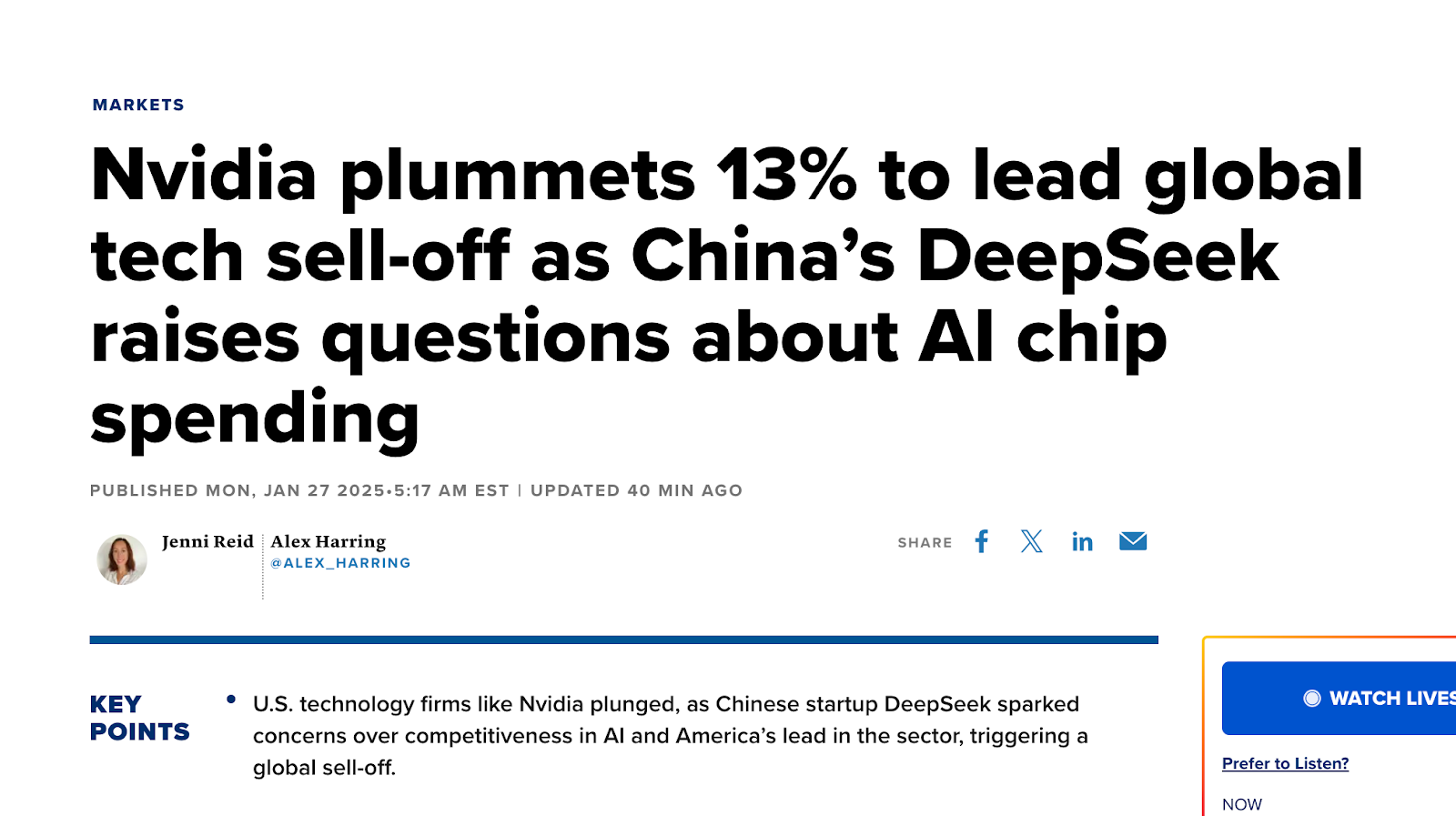
DeepSeek’s innovative use of chips and improved learning algorithms challenges previous assumptions. Do we actually need 500 billion dollars worth of data centers if we can train powerful models for a fraction of the cost? Perhaps, perhaps not.
This is not a story about China vs. US
Last week, Scale AI CEO Alexandr Wang took out a full-page ad in The Washington Post that said: “President Trump, America must win the AI War”.
While it might be tempting to look at these developments through the lens of an AI arms race – the fact that DeepSeek open sourced its models, basically giving away its secrets to the world (including the US), appears to counter this narrative.
Even if you don’t find this a compelling argument, limiting access did not stifle innovation or help sustain the advantage many had thought America had. The more interesting trend is that open source is inadvertently leading to increased commoditization: a development that is good news for people building stuff, but spells trouble for companies in the business of selling inference.
DeepSeek’s release also competes on a product level. OpenAI’s o1 is available to Plus or Pro subscribers through ChatGPT. Pro is the newest $200 dollar/month tier, which gives people access to o1 without rate limits as well as a more powerful version that thinks for longer. Seeing what DeepSeek-R1 is capable of and how efficient it is – and the fact that everyone in the world can access it for free (!) – this $200 dollar/month subscription suddenly feels terribly overpriced. To no one’s surprise, DeepSeek’s chatbot has quickly risen to the number 1 spot for most downloaded app.
In the same aforementioned interview with DeepSeek CEO Liang Wenfeng, he was also asked about his intentions to monetize (or the lack thereof). To this, he offered this poetic response: “An exciting endeavor perhaps cannot be measured purely in monetary terms. It’s like someone buying a piano for a home—first, they can afford it, and second, such a group of people are eager to play beautiful music on it.”
A beautiful note to end things on. Enjoy the music, folks.
Can I finally go on my Lunar Year break now? 🧧
🐋 More DeepSeek Reads
-
Five things most people don’t seem to understand about DeepSeek
-
7 Implications of DeepSeek’s Victory Over American AI Companies
-
DeepSeek isn’t a victory for the AI sceptics
-
Alibaba launches new AI model targeting rival DeepSeek, China’s hottest start-up
Read More in AI Supremacy

{kind=link}